
文章目录
[+]
import java.util.regex.Matcher; import java.util.regex.Pattern; public class HtmlParser { public static void main(String[] args) { String html = "<html><head><title>My Website</title></head><body><p>This is some sample text.</p></body></html>"; Pattern pattern = Pattern.compile("<p[^>]>(.?)</p>"); Matcher matcher = pattern.matcher(html); String pText = matcher.group(1); System.out.println(pText); } }
在上面的代码中,我们首先定义了一个HTML字符串,然后利用Pattern和Matcher类来匹配HTML中的文本。Pattern类用于定义正则表达式,Matcher类用于在HTML中查找匹配的文本。
在正则表达式中,我们利用了<p[^>]>来匹配以<p>开头,后面随着任意数量的字符,再以</p>结尾的文本。个中,[^>]表示匹配任意数量的字符,</p>表示匹配</p>后面的任意字符。

末了,我们利用group(1)方法来获取匹配的文本,并将其打印到掌握台上。
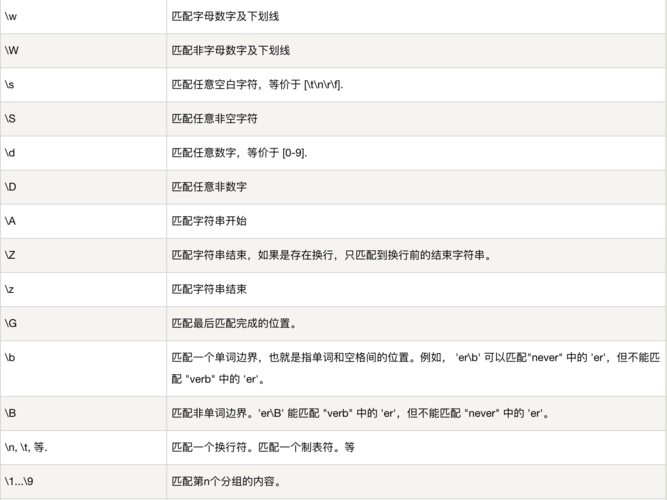
(图片来自网络侵删)
须要把稳的是,正则表达式可以根据HTML标签的不同来进行不同的















