
作者:萨扬·穆霍帕迪亚(Sayan Mukhopadhyay)
如需转载请联系华章科技

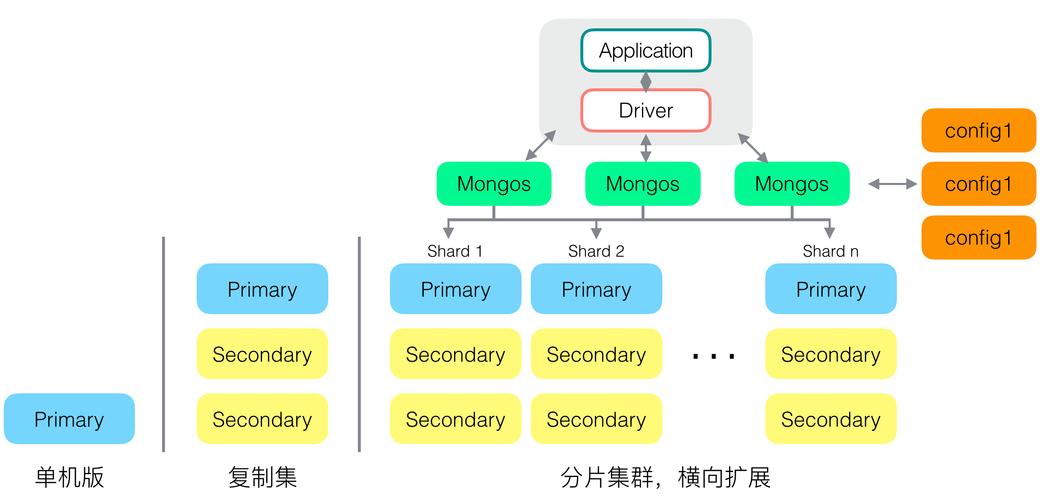
MongoDB是一个开源文档数据库,旨在实现卓越的性能、易用性和自动扩展。MongoDB确保不须要工具关系映射(ORM)来促进开拓。包含由字段和值对组成的数据构造的文档在MongoDB中称为记录(record)。这些记录类似于JSON工具。字段的值可以包括其他文档、数组和文档数组。
{ \公众_id\"大众:ObjectId(\"大众01\公众),\"大众address\公众: {\"大众street\"大众:\"大众Siraj Mondal Lane\公众,\公众pincode\公众:\公众743145\"大众,\"大众building\"大众:\"大众129\"大众,\公众coord\"大众: [ -24.97, 48.68 ] },\公众borough\公众:\"大众Manhattan\"大众,
1. 将数据导入凑集
mongoimport可利用系统脚本或命令提示符将文档放入数据库的凑集中。如果凑集预先存在于数据库中,操作将首先丢弃原始凑集。
mongoimport --DB test --collection restaurants --drop --file ~/ downloads/primer-dataset.json
mongoimport命令连接到端口号为27017确当地运行的MongoDB实例。选项 --file 供应了导入数据的方法,此处为 ~/downloads/primer-dataset.json。
要将数据导入到运行在不同主机或端口上的MongoDB实例中,须要在 mongoimport 命令中特殊指出主机名或端口,用选项 --host 或 --port。
MySQL中有类似的命令load。
2. 利用pymongo创建连接
要创建连接,请实行以下操作:
import MongoClient from pymongo.Client11 = MongoClient()
如果MongoClient无参数,那么将默认在端口27017上确当地端口上运行MongoDB实例。
可以指定一个完全的MongoDB URL来定义连接,个中包括主机和端口号。例如,下面的代码会连接到一个MongoDB实例,该实例运行在 mongodbo.example.net 的27017端口上:
Client11 = MongoClient(\"大众mongodb://myhostname:27017\"大众)
3. 访问数据库工具
要将名为primer的数据库分配给局部变量DB,可以利用以下任意一行代码:
Db11 = client11.primerdb11 = client11['primer']
凑集工具可以通过字典或数据库工具属性进行访问,如以下两个示例所示:
Coll11 = db11.datasetcoll = db11['dataset']
4. 插入数据
你可以将文档放入目前不存在的凑集中,以下操作将创建凑集:
result=db.addrss.insert_one({<<your json >>)
5. 更新数据
以下是更新数据的方法:
result=db.address.update_one({\"大众building\公众: \"大众129\"大众,{\"大众$set\"大众: {\"大众address.street\公众: \公众MG Road\"大众}})
6. 删除数据
要从凑集中删除所有文档,请利用以下命令:
result=db.restaurants.delete_many({})02 Pandas
下面展示一些示例,以便你开始利用Pandas。这些示例取自现实天下的数据,数据上自然会有一些瑕疵。Pandas是受R数据框架观点启示形成的框架。
要从CSV文件中读取数据,请利用以下命令:
import pandas as pdbroken_df=pd.read_csv('data.csv')
要查看前三行,请利用:
broken_df[:3]
要选择列,请利用:
fixed_df['Column Header']
要绘制列,请利用:
fixed_df['Column Header'].plot()
要获取数据集中的最大值,请利用以下命令:
MaxValue=df['Births'].max() where Births is the column header
假设数据集中有另一列名为Name,Name的命令与最大值干系联。
MaxName=df['Names'][df['Births']==df['Births'].max()].values
在Pandas中还有许多其他方法,例如 sort、groupby 和 orderby,它们对付构造化数据的利用很有用。此外,Pandas还有一个现成的适配器,适用于MongoDB、Google Big Query等盛行数据库。
接下来将展示一个与Pandas干系的繁芜示例。在不同列值的X数据框中,查找root列分组的均匀值。
for col in X.columns: if col != 'root': avgs = df.groupby([col,'root'], as_index=False)['floor'].aggregate(np.mean) for i,row in avgs.iterrows(): k = row[col] v = row['floor'] r = row['root'] X.loc[(X[col] == k) & (X['root'] == r), col] = v2.
关于作者:Sayan Mukhopadhyay拥有超过13年的行业履历,并与瑞信、PayPal、CA Technologies、CSC和Mphasis等公司建立了联系。他对投资银行、在线支付、在线广告、IT架构和零售等领域的数据剖析运用有着深刻的理解。他的专业领域是在分布式和数据驱动的环境(如实时剖析、高频交易等)中,实现高性能打算。
本文摘编自《Python高等数据剖析:机器学习、深度学习和NLP实例》,经出版方授权发布。
延伸阅读《Python高等数据剖析》
推举语:本书先容高等数据剖析观点的广泛根本,以及最近的数据库革命,如Neo4j、弹性搜索和MongoDB。本书谈论了如何实现包括局部爬取在内的ETL技能,并运用于高频算法交易和目标导向的对话系统等领域。还有一些机器学习观点的例子,如半监督学习、深度学习和NLP。本书还涵盖了主要的传统数据剖析技能,如韶光序列和主身分剖析等。















