推举学习1:中间件合集:MQ(ActiveMQ/RabbitMQ/RocketMQ)+Kafka+条记
推举学习2:数据库中间件:Mycat 威信指南+Mycat 实战条记,左右开弓
推举学习3:“68道 Redis+168道 MySQL”佳构口试题(带解析),你背废了吗?
02 先容(图片来自网络侵删)RabbitMQ是由erlang措辞开拓,基于AMQP(Advanced Message Queue 高等行列步队协议)协议实现的行列步队。
为什么利用RabbitMQ呢?
使得大略,功能强大。基于AMQP协议。社区生动,文档完善。高并发性能好,这紧张得益于Erlang措辞。Spring Boot默认已集成RabbitMQ03 AMQP协议3.1 AMQP基本先容AMQP,即Advanced Message Queuing Protocol,一个供应统一做事的运用层标准高等行列步队协议,是运用层协议的一个开放标准,为面向的中间件设计。基于此协议的客户端与中间件可通报,并不受客户端/中间件同产品、不同的开拓措辞等条件的限定。
AMQP的实现有:RabbitMQ、OpenAMQ、Apache Qpid、Redhat Enterprise MRG、AMQP Infrastructure、ØMQ、Zyre等。
目前Rabbitmq最新的版本默认支持的是AMQP 0-9-1,该协议统共包含了3部分:
Module Layer: 位于协议的最高层,紧张定义了一些供客户端调用的命令,客户端可以利用这些命令实现自定义的业务逻辑。例如,客户端可以是利用Queue.Declare命令声明一个行列步队或者利用Basic.Consume订阅消费一个行列步队中的。
Session Layer: 位于中间层,紧张卖力将客户真个命令发送给做事端,再将做事真个应答返回给客户端,紧张为客户端与做事器之间的通信供应可靠性的同步机制和缺点处理。
Transport Layer: 位于最底层,紧张传输二进制数据流,供应帧的处理、信道的复用、缺点检讨和数据表示等。
3.2 AMQP生产者流转过程当客户端与Broker建立连接的时候,客户端会向Broker发送一个Protocol Header 0-9-1的报文头,以此关照Broker本次交互才采取的是AMQP 0-9-1协议。
紧接着Broker返回Connection.Start来建立连接,在连接的过程中涉及Connection.Start/.Start-OK、Connection. Tune/. Tune-OK、Connection.Open/.Open-OK这6个命令的交互。
连接建立往后须要创建通道,会利用到Channel.Open , Channel.Open-OK命令,在进行交流机声明的时候须要利用到Exchange.Declare以及Exchange.Declare-OK的命令。以此类推,在声明行列步队以及完成行列步队和交流机的绑定的时候都会利用到指定的命令来完成。
在进行发送的时候会利用到Basic.Publish命令完成,这个命令还包含了Conetent-Header和Content-Body。Content Header里面包含的是体的属性,Content-Body包含了体本身。
3.3 AMQP消费者流转过程消费者消费的时候,所涉及到的命令和天生者大部分都是相同的。在原有的根本之上,多个几个命令:Basic.Qos/.Qos-OK以及Basic.Consume和Basic.Consume-OK。
个中Basic.Qos/.Qos-OK这两个命令紧张用来确认消费者最大能保持的未确认的数时利用。Basic.Consume和Basic.Consume-OK这两个命令紧张用来进行消费确认。
04 RabbitMQ的特性RabbitMQ利用Erlang措辞编写,利用Mnesia数据库存储。(1)可靠性(Reliability) RabbitMQ 利用一些机制来担保可靠性,如持久化、传输确认、发布确认。(2)灵巧的路由(Flexible Routing) 在进入行列步队之前,通过Exchange 来路由的。对付范例的路由功能,RabbitMQ 已经供应了一些内置的Exchange 来实现。针对更繁芜的路由功能,可以将多个Exchange 绑定在一起,也通过插件机制实现自己的Exchange。(3)集群(Clustering) 多个RabbitMQ 做事器可以组成一个集群,形成一个逻辑Broker 。(4)高可用(Highly Available Queues) 行列步队可以在集群中的机器上进行镜像,使得在部分节点出问题的情形下行列步队仍旧可用。(5)多种协议(Multi-protocol) RabbitMQ 支持多种行列步队协议,比如AMQP、STOMP、MQTT 等等。(6)多措辞客户端(Many Clients) RabbitMQ 险些支持所有常用措辞,比如Java、.NET、Ruby、PHP、C#、JavaScript 等等。(7)管理界面(Management UI) RabbitMQ 供应了一个易用的用户界面,使得用户可以监控和管理、集群中的节点。(8)插件机制(Plugin System)RabbitMQ供应了许多插件,以实现从多方面扩展,当然也可以编写自己的插件。
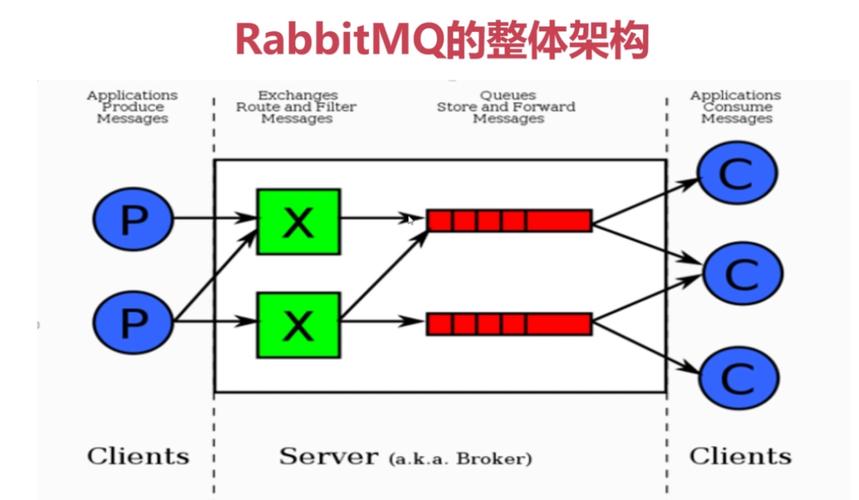
05 事情模型名词阐明Broker :即RabbitMQ的实体做事器。供应一种传输做事,掩护一条从生产者到消费者的传输线路,担保数据能按照指定的办法传输。Exchange :交流机。指定按照什么规则路由到哪个行列步队Queue。Queue :行列步队。的载体,每条都会被投送到一个或多个行列步队中。Binding :绑定。浸染便是将Exchange和Queue按照某种路由规则绑定起来。Routing Key:路由关键字。Exchange根据Routing Key进行投递。定义绑定时指定的关键字称为Binding Key。Vhost:虚拟主机。一个Broker可以有多个虚拟主机,用作不同用户的权限分离。一个虚拟主机持有一组Exchange、Queue和Binding。Producer:生产者。紧张将投递到对应的Exchange上面。一样平常是独立的程序。Consumer:消费者。的吸收者,一样平常是独立的程序。Connection:Producer 和Consumer 与Broker之间的TCP长连接。Channel:通道,也称信道。在客户真个每个连接里可以建立多个Channel,每个Channel代表一个会话任务。在RabbitMQ Java Client API中,channel上定义了大量的编程接口。
5.1 交流机类型Direct Exchange 直连交流机
定义:直连类型的交流机与一个行列步队绑定时,须要指定一个明确的binding key。路由规则:发送到直连类型的交流机时,只有routing key跟binding key完备匹配时,绑定的行列步队才能收到。
Topic Exchange 主题交流机定义:主题类型的交流机与一个行列步队绑定时,可以指定按模式匹配的routing key。通配符有两个,代表匹配一个单词。#代表匹配零个或者多个单词。单词与单词之间用 . 隔开。路由规则:发送到主题类型的交流机时,routing key符合binding key的模式时,绑定的行列步队才能收到。
// 只有行列步队1能收到channel.basicPublish("MY_TOPIC_EXCHANGE", "sh.abc", null, msg.getBytes()); // 行列步队2和行列步队3能收到channel.basicPublish("MY_TOPIC_EXCHANGE", "bj.book", null, msg.getBytes()); // 只有行列步队4能收到channel.basicPublish("MY_TOPIC_EXCHANGE", "abc.def.food", null, msg.getBytes());Fanout Exchange 广播交流机
定义:广播类型的交流机与一个行列步队绑定时,不须要指定binding key。路由规则:当发送到广播类型的交流机时,不须要指定routing key,所有与之绑定的行列步队都能收到。
06 RabbitMq安装
下载镜像
docker pull rabbitmq创建并启动容器
docker run -d --name rabbitmq -p 5672:5672 -p 15672:15672 -v `pwd`/data:/var/lib/rabbitmq --hostname myRabbit -e RABBITMQ_DEFAULT_VHOST=my_vhost -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=admin rabbitmq-d 后台运行容器;--name 指定容器名;-p 指定做事运行的端口(5672:运用访问端口;15672:掌握台Web端口号);-v 映射目录或文件;--hostname 主机名(RabbitMQ的一个主要把稳事变是它根据所谓的 “节点名称” 存储数据,默认为主机名);-e 指定环境变量;(RABBITMQ_DEFAULT_VHOST:默认虚拟机名;RABBITMQ_DEFAULT_USER:默认的用户名;RABBITMQ_DEFAULT_PASS:默认用户名的密码)启动rabbitmq后台管理做事
docker exec -it rabbitmq rabbitmq-plugins enable rabbitmq_management访问后台页面:
07 RabbitMQ快速入门
http://127.0.0.1:15672 初始密码: admin adminmaven依赖
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> <version>2.3.0.RELEASE</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> <version>2.3.0.RELEASE</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-amqp</artifactId> <version>2.3.0.RELEASE</version> </dependency> </dependencies>rabbitmq配置类
/ @author 原 @date 2020/12/22 @since 1.0 /@Configurationpublic class RabbitConfig { public static final String EXCHANGE_TOPICS_INFORM = "exchange_topic_inform"; public static final String QUEUE_SMS = "queue_sms"; public static final String QUEUE_EMAIL = "queue_email"; @Bean public Exchange getExchange() { //durable(true)持久化,行列步队重启后交流机仍旧存在 return ExchangeBuilder.topicExchange(EXCHANGE_TOPICS_INFORM).durable(true).build(); } @Bean("queue_sms") public Queue getQueueSms(){ return new Queue(QUEUE_SMS); } @Bean("queue_email") public Queue getQueueEmail(){ return new Queue(QUEUE_EMAIL); } @Bean public Binding bindingSms(@Qualifier("queue_sms") Queue queue, Exchange exchange){ return BindingBuilder.bind(queue).to(exchange).with("demo.#.sms").noargs(); } @Bean public Binding bindingEmail(@Qualifier("queue_email") Queue queue, Exchange exchange){ return BindingBuilder.bind(queue).to(exchange).with("demo.#.email").noargs(); }}生产者
@Servicepublic class RabbitmqProviderService { @Autowired RabbitTemplate rabbitTemplate; public void sendMessageSms(String message) { rabbitTemplate.convertAndSend(RabbitConfig.EXCHANGE_TOPICS_INFORM,"demo.one.sms",message); } public void sendMessageEmail(String message) { rabbitTemplate.convertAndSend(RabbitConfig.EXCHANGE_TOPICS_INFORM,"demo.one.email",message); }}消费者
@Componentpublic class RabbitMqConsumer { @RabbitListener(queues = {RabbitConfig.QUEUE_EMAIL}) public void listenerEmail(String message, Message msg , Channel channel) { System.out.println("EMAIL:"+message); System.out.println(msg); System.out.println(channel); } @RabbitListener(queues = {RabbitConfig.QUEUE_SMS}) public void listenerSms(String message) { System.out.println("SMS:"+message); }}启动类
/ @author 原 @date 2020/12/22 @since 1.0 /@SpringBootApplication@EnableRabbitpublic class RabbitMqApplicaiton { public static void main(String[] args) { ResourceLoader resourceLoader = new DefaultResourceLoader(RabbitMqApplicaiton.class.getClassLoader()); try { String path = resourceLoader.getResource("classpath:").getURL().getPath(); System.out.println(path); } catch (IOException e) { e.printStackTrace(); } SpringApplication.run(RabbitMqApplicaiton.class, args); }}web
@RestControllerpublic class DemoController { @Autowired RabbitmqProviderService rabbitmqProviderService; @RequestMapping("/sms") public void sendMsgSms(String msg) { rabbitmqProviderService.sendMessageSms(msg); } @RequestMapping("/eamil") public void sendMsgEmail(String msg) { rabbitmqProviderService.sendMessageEmail(msg); }}通过页面发送:
http://localhost:44000/sms?msg=1111
http://localhost:44000/email?msg=1111
08 RabbitMQ进阶用法8.1 TTL设置过期韶光
MessageProperties messageProperties = new MessageProperties();messageProperties.setExpiration("30000");Message msg = new Message("内容".getBytes(),messageProperties);//如果没有及时消费,那么经由30秒往后,变成去世信,Rabbitmq会将这个直接丢弃。rabbitTemplate.convertAndSend(RabbitConfig.EXCHANGE_TOPICS_INFORM,"demo.one.sms",msg);行列步队设置过期韶光
Queue queue = QueueBuilder.durable(QUEUE_SMS).ttl(30000).build();去世信行列步队当一个变成去世信了往后,默认情形下这个会被mq删除。如果我们给行列步队指定了"去世信交流机"(DLX:Dead-Letter-Exchange),那么此时这个就会转发到去世信交流机,进而被与去世信交流机绑定的行列步队(去世信行列步队)进行消费。从而实现了延迟发送的效果。有三种情形会进入DLX(Dead Letter Exchange)去世信交流机。1、(NACK || Reject ) && requeue == false2、过期3、行列步队达到最大长度,可以通过x-max-length参数来指定行列步队的长度,如果不指定,可以认为是无限长(先入队的会被发送到DLX)
1、声明去世信交流机、去世信行列步队、去世信交流机和去世信行列步队的绑定
// 声明去世信交流机@Bean(name = "dlx.exchange")public Exchange dlxExchange() {returnExchangeBuilder.directExchange("dlx.exchange").durable(true).build() ;}// 声明去世信行列步队@Bean(name = "dlx.queue")public Queue dlxQueue() { return QueueBuilder.durable("dlx.queue").build() ;}// 完成去世信行列步队和去世信交流机的绑定@Beanpublic Binding dlxQueueBindToDlxExchange(@Qualifier(value ="dlx.exchange") Exchange exchange, @Qualifier(value = "dlx.queue")Queue queue) { returnBindingBuilder.bind(queue).to(exchange).with("delete").noargs() ;}2、将去世信行列步队作为普通行列步队的属性设置过去
// 声明行列步队@Bean(name = "direct.queue_02")public Queue commonQueue02() { QueueBuilder queueBuilder =QueueBuilder.durable("direct.queue_02"); queueBuilder.deadLetterExchange("dlx.exchange") ; // 将去世信交流机作为普通行列步队的属性设置过去 queueBuilder.deadLetterRoutingKey("delete") ; // 设置的routingKey // queueBuilder.ttl(30000) ; // 设置行列步队的过期韶光,为30秒 // queueBuilder.maxLength(2) ; // 设置行列步队的最大长度 return queueBuilder.build() ;}3、消费端进行同样的设置,并且指定消费去世信行列步队
@Componentpublic class RabbitmqDlxQueueConsumer{ // 创建日志记录器 private static final Logger LOGGER =LoggerFactory.getLogger(RabbitmqDlxQueueConsumer.class) ; @RabbitListener(queues = "dlx.queue") public void dlxQueueConsumer(String msg) { LOGGER.info("dlx queue msg is : {} ", msg); }}优先行列步队优先级高的可以优先被消费,但是:只有堆积(的发送速率大于消费者的消费速率)的情形下优先级才故意义。
Map<String, Object> argss = new HashMap<String, Object>();argss.put("x-max-priority",10); // 行列步队最大优先级channel.queueDeclare("ORIGIN_QUEUE", false, false, false, argss);延迟行列步队RabbitMQ本身不支持延迟行列步队。可以利用TTL结合DLX的办法来实现的延迟投递,即把DLX跟某个行列步队绑定,到了指定时间,过期后,就会从DLX路由到这个行列步队,消费者可以从这个行列步队取走。另一种办法是利用rabbitmq-delayed-message-exchange插件。当然,将须要发送的信息保存在数据库,利用任务调度系统扫描然后发送也是可以实现的。
做事端限流在AutoACK为false的情形下,如果一定数目的(通过基于consumer或者channel设置Qos的值)未被确认前,不进行消费新的。
channel.basicQos(2); // 如果超过2条没有发送ACK,当前消费者不再接管行列步队channel.basicConsume(QUEUE_NAME, false, consumer);09 RabbitMQ如何担保可靠性首先须要明确,效率与可靠性是无法兼得的,如果要担保每一个环节都成功,势必会对的收发效率造成影响。如果是一些业务履行同等性哀求不是特殊高的场合,可以捐躯一些可靠性来换取效率。
① 代表从生产者发送到Exchange;② 代表从Exchange路由到Queue;③ 代表在Queue中存储;④ 代表消费者订阅Queue并消费。
9.1 确保发送到RabbitMQ做事器可能由于网络或者Broker的问题导致①失落败,而生产者是无法知道是否精确发送到Broker的。
有两种办理方案,第一种是Transaction(事务)模式,第二种Confirm(确认)模式。
在通过channel. txSelect方法开缘由务之后,我们便可以发布给RabbitMQ了,如果事务提交成功,则定到达了RabbitMQ中,如果在事务提交实行之前由于RabbitMQ非常崩溃或者其他缘故原由抛出非常,这个时候我们便可以将其捕获,进而通过实行channel. txRollback方法来实现事务回滚。利用事务机制的话会“吸干”RabbitMQ性能,一样平常不建议利用。
生产者通过调用channel. confirmSelect方法(即Confirm. Select命令)将信道设置为confirm模式。一旦投递到所有匹配的行列步队之后,RabbitMQ就会发送一个确认(Basic. Ack)给生产者(包含的唯一ID),这就使得生产者知晓已经精确到达了目的地了。
9.2 确保路由到精确的行列步队可能由于路由关键字缺点,或者行列步队不存在,或者行列步队名称缺点导致②失落败。利用mandatory参数和ReturnListener,可以实现无法路由的时候返回给生产者。另一种办法便是利用备份交流机(alternate-exchange),无法路由的会发送到这个交流机上。
9.3 确保在行列步队精确地存储可能由于系统宕机、重启、关闭等等情形导致存储在行列步队的丢失,即③涌现问题。
1、做行列步队、交流机、的持久化。
2、做集群,镜像行列步队。
如果想变动这个默认的配置,我们可以在/etc/rabbitmq/目录下创建一个rabbitmq.config文件,配置信息可以按照指定的json规则进行指定。如下所示:
[{ rabbit, [ { queue_index_embed_msgs_below, 4097 } ]}].然后重启rabbitmq做事(rabbitmqctl stop----> rabbitmq-server -detached)。那么我们是不是把queue_index_embed_msgs_below参数的值调节的越大越好呢?肯定不是的rabbit_queue_index中以顺序(文件名从0开始累加)的段文件来进行存储,后缀为".idx",每个段文件中包含固定的SEGMENT_ENTRY_COUNT条记录,SEGMENT_ENTRY_COUNT默认值为16384。每个rabbit_queue_index从磁盘中读取消息的时候至少在内存中掩护一个段文件,以是设置queue_index_embed_msgs_below值的时候须要格外谨慎,一点点增大也可能会引起内存爆炸式增长。
干系知识:存储机制
不管是持久化的还是非持久化的都可以被写入到磁盘。1、持久化的在到达行列步队时就被写入到磁盘,并且如果可以,持久化的也会在内存中保存一份备份,这样可以提高一定的性能,当内存急急的时候会从内存中打消。2、非持久化的一样平常只保存在内存中,在内存急急的时候会被写入到磁盘中,以节省内存空间。这两种类型的的落盘处理都在RabbitmqMQ的"持久层"中完成。持久层的组成如下所示:
rabbit_queue_index:卖力掩护行列步队中的落盘的信息,包括的存储地点、是否已被交付给消费者、是否已被消费者ack。每一个行列步队都有与之对应的一个rabbitmq_queue_index。rabbit_msg_store: 卖力的存储,它被所有的行列步队共享,在每个节点中有且只有一个。rabbit_msg_store可以在进行细分:
msg_store_persisent :卖力持久化的持久化,重启不会丢失
msg_store_transient :卖力非持久化的持久化,重启会丢失
可以存储在rabbit_queue_index中也可以存储在rabbit_msg_store中。最佳的配置是较小的存储在rabbit_queue_index中而较大的存储在rabbit_msg_store中。这个的界定可以通过queue_index_embed_msgs_below来配置,默认大小为4096,单位为B。把稳这里的大小是指体、属性以及headers整体的大小。当一个小于设定的大小阈值时就可以存储在rabbit_queue_index中,这样可以得到性能上的优化。这种存储机制是在Rabbitmq3.5 版本往后引入的,该优化提高了系统性能10%旁边。
干系知识: 行列步队的构造
Rabbitmq中行列步队的是由两部分组成:rabbit_amqpqueue_process和backing_queue组成:
rabbit_amqpqueue_process: 卖力协议干系的处理,即吸收生产者发布的、向消费者交付、处理的确认(包括生产真个confirm和消费真个ack)等。backing_queue: 是存储的详细形式和引擎,并向rabbit_amqpqueue_process供应干系的接口以供调用。
如果发送的行列步队是空的且行列步队有消费者,该不会经由该行列步队而是直接发往消费者,如果无法直接被消费,则须要将暂存入行列步队,以便重新投递。
在存入行列步队后,紧张有以下几种状态:alpha:内容(包括体、属性和headers)和索引都存在内存中(花费内存最多,CPU花费最少)beta:内容保存在磁盘中,索引都存在内存中(只须要一次IO操作就可以读取到)gamma:内容保存在磁盘中,索引在磁盘和内存中都存在(只须要一次IO操作就可以读取到)delta:内容和索引都在磁盘中(花费内存最小,但是会花费更多的CPU和磁盘的IO操作)持久化的,内容和索引必须先保存在磁盘中,才会处于上面状态中的一种,gamma状态只有持久化的才有这种状态。Rabbitmq在运行时会根据统计的传送速率定期打算一个当前内存中能够保存的最大数量(target_ram_count), 如果alpha状态的数量大于此值时,就会引起的状态转换,多余的可能会转换到beta状态、gamma状态或者delta状态。区分这4种状态的紧张浸染是知足不同的内存和CPU 的需求。
对付普通行列步队而言,backing_queue内部的实现是通过5个子行列步队来表示的状态的:Q1:只包含alpha状态的Q2:包含beta和gamma的Delta:包含delta的Q3:包含beta和gamma的Q4:只包含alpha状态的
一样平常情形下,按照Q1->Q2->Delta->Q3->Q4这样的顺序进行流动,但并不是每一条都会经历所有状态,这取决于当前系统的负载情形(比如非持久化的在内存负载不高时,就不会经历delta)。如此设计的好处:可以在行列步队负载很高的情形下,能够通过将一部分由磁盘保存来节省内存空间,而在负载降落的时候,这部分又逐渐回到内存被消费者获取,使得全体行列步队具有良好的弹性。
干系知识: 消费时的状态转换
消费者消费也会引起状态的转换,状态转换的过程如下所示:
消费者消费时先从Q4获取消息,如果获取成功则返回。如果Q4为空,则从Q3中获取消息,首先判断Q3是否为空,如果为空返回行列步队为空,即此时行列步队中无如果Q3不为空,取出Q3的,然后判断Q3和Delta中的长度,如果都为空,那么Q2、Delta、Q3、Q4都为空,直接将Q1中的转移至Q4,下次直接从Q4中读取消息如果Q3为空,Delta不为空,则将Delta中的转移至Q3中,下次直接从Q3中读取。在将从Delta转移至Q3的过程中,是按照索引分段读取,首先读取某一段,然后判断读取的个数和Delta的个数,如果相等,剖断Delta已无,直接将读取Q2和读取到一并放入Q3,如果不相等,仅将这次读取的转移到Q3。常日在负载正常时,如果被消费的速率不小于吸收新的速率,对付不须要担保可靠性的来说,极有可能只会处于alpha状态。对付durable属性设置为true的,它一定会进入gamma状态,并且在开启publisher confirm机制时,只有到了gamma状态时才会确认该己被吸收,若消费速率足够快、内存也充足,这些也不会连续走到下一个状态。
在系统负载较高中,已经收到的若不能很快被消费掉,便是这些便是在行列步队中"堆积", 那么此时Rabbitmq就须要花更多的韶光和资源处理"堆积"的,如此用来处理新流入的的能力就会降落,使得流入的又被"堆积"连续增大处理每个的均匀开销,继而情形变得越来越恶化,使得系统的处理能力大大降落。减少堆积的常见地决方案:1、增加prefetch_count的值,设置消费者存储未确认的的最大值2、消费者进行multiple ack,降落ack带来的开销
干系知识: 惰性行列步队
默认情形下,当生产者将发送到Rabbitmq的时候,行列步队中的会尽可能地存储在内存中,这样可以更快地将发送给消费者。纵然是持久化的,在被写入磁盘的同时也会在内存中驻留一份备份。这样的机制无形会占用更多系统资源,毕竟内存该当留给更多有须要的地方。如果发送端过快或消费端宕机,导致大量积压,此时还是在内存和磁盘各存储一份,在大爆发的时候,MQ做事器会撑不住,影响其他行列步队的收发,能不能有效的处理这种情形呢。答案 惰性行列步队。RabbitMQ从3.6.0版本开始引入了惰性行列步队(Lazy Queue)的观点。惰性行列步队会将吸收到的直接存入文件系统中,而不管是持久化的或者是非持久化的,这样可以减少了内存的花费,但是会增加I/0的利用,如果是持久化的,那么这样的I/0操作不可避免,惰性行列步队和持久化的可谓是"最佳拍档"。把稳如果惰性行列步队中存储的是非持久化的,内存的利用率会一贯很稳定,但是重启之后一样会丢失。把一个行列步队设置成惰性行列步队的办法:
// 声明行列步队@Bean(name = "direct.queue_03")public Queue commonQueue03() { QueueBuilder queueBuilder = QueueBuilder.durable("direct.queue_03"); queueBuilder.lazy(); // 把行列步队设置成惰性行列步队 return queueBuilder.build();}9.4 确保从行列步队精确地投递到消费者如果消费者收到后未来得及处理即发生非常,或者处理过程中发生非常,会导致④失落败。
为了担保从行列步队可靠地达到消费者,RabbitMQ供应了确认机制(message acknowledgement)。消费者在订阅行列步队时,可以指定autoAck参数,当autoAck即是false时,RabbitMQ会等待消费者显式地回答确认旗子暗记后才从行列步队中移去。
如果消费失落败,也可以调用Basic. Reject或者Basic. Nack来谢绝当前而不是确认。如果r equeue参数设置为true,可以把这条重新存入行列步队,以便发给下一个消费者(当然,只有一个消费者的时候,这种办法可能会涌现无限循环重复消费的情形,可以投递到新的行列步队中,或者只打印非常日志)。
9.5 补偿机制对付一定韶光没有得到相应的,可以设置一个定时重发的机制,但要掌握次数,比如最多重发3次,否则会造成堆积。
9.6 幂等性做事端是没有这种掌握的,只能在消费端掌握。如何避免的重复消费?重复可能会有两个缘故原由:1、生产者的问题,环节①重复发送,比如在开启了Confirm模式但未收到确认。2、环节④出了问题,由于消费者未发送ACK或者其他缘故原由,重复投递。对付重复发送的,可以对每一条天生一个唯一的业务ID,通过日志或者建表来做重复掌握。
9.7 的顺序性的顺序性指的是消费者消费的顺序跟生产者产生的顺序是同等的。在RabbitMQ中,一个行列步队有多个消费者时,由于不同的消费者消费的速率是不一样的,顺序无法担保。
10 RabbitMQ如何担保高可用10.1 RabbittMQ集群集群紧张用于实现高可用与负载均衡。RabbitMQ通过/var/lib/r abbitmq/. erlang. cookie来验证身份,须要在所有节点上保持同等。集群有两种节点类型,一种是磁盘节点,一种是内存节点。集群中至少须要一个磁盘节点以实现元数据的持久化,未指定类型的情形下,默认为磁盘节点。集群通过25672端口两两通信,须要开放防火墙的端口。须要把稳的是,RabbitMQ集群无法搭建在广域网上,除非利用feder ation或者shovel等插件。集群的配置步骤:1、配置hosts2、同步erlang. cookie3、加入集群
集群搭建
docker pull rabbitmq:3.6.10-management
docker run -di --network=docker-network --ip=172.19.0.50 --hostname=rabbitmq-node01 --name=rabbitmq_01 -p 15673:15672 -p 5673:5672--privileged=true -e RABBITMQ_ERLANG_COOKIE='rabbitcookie'rabbitmq:3.6.10-management /bin/bashdocker run -di --network=docker-network --ip=172.19.0.51 --hostname=rabbitmq-node02 --name=rabbitmq_02 -p 15674:15672 -p 5674:5672--privileged=true -e RABBITMQ_ERLANG_COOKIE='rabbitcookie'rabbitmq:3.6.10-management /bin/bashdocker run -di --network=docker-network --ip=172.19.0.52 --hostname=rabbitmq-node03 --name=rabbitmq_03 -p 15675:15672 -p 5675:5672--privileged=true -e RABBITMQ_ERLANG_COOKIE='rabbitcookie'rabbitmq:3.6.10-management /bin/bash参数解释:Erlang Cookie值必须相同,也便是RABBITMQ_ERLANG_COOKIE参数的值必须相同。由于RabbitMQ是用Erlang实现的,Erlang Cookie相称于不同节点之间相互通讯的秘钥,Erlang节点通过交流Erlang Cookie得到认证。
docker exec -itrabbitmq_01 /bin/bash配置hosts文件,让各个节点都能互相识别对方的存在。在系统中编辑/etc/hosts文件,添加ip地址和节点名称的映射信息(apt-get update , apt-get install vim):
172.19.0.50 rabbitmq-node01172.19.0.51 rabbitmq-node02172.19.0.52 rabbitmq-node03启动rabbitmq,并且查看状态
root@014faa4cba72:/# rabbitmq-server -detached # 启动rabbitmq做事,该命令可以启动erlang虚拟机和rabbitmq做事root@014faa4cba72:/# rabbitmqctl status # 查看节点信息Status of noderabbit@014faa4cba72[{pid,270},{running_applications, [{rabbitmq_management,"RabbitMQ Management Console","3.6.10"}, {rabbitmq_management_agent,"RabbitMQ Management Agent","3.6.10"}, {rabbitmq_web_dispatch,"RabbitMQ Web Dispatcher","3.6.10"},.............root@014faa4cba72:/# rabbitmqctl cluster_status # 查看集群节点状态Cluster status of noderabbit@014faa4cba72[{nodes,[{disc,[rabbit@014faa4cba72]}]},{running_nodes,[rabbit@014faa4cba72]}, # 正在运行的只有一个节点{cluster_name,<<"rabbit@014faa4cba72">>},{partitions,[]},{alarms,[{rabbit@014faa4cba72,[]}]}]把稳:此时我们可以通过浏览器访问rabbitmq的后端管理系统,但是rabbitmq默认供应的guest用户不支持远程访问。因此我们须要创建用户,并且对其进行授权
root@014faa4cba72:/# rabbitmqctl add_user admin admin # 添加用户,用户名为admin,密码为adminroot@014faa4cba72:/# rabbitmqctl list_users # 查看rabbitmq的用户列表Listing usersadmin [] # admin用户已经添加成功,但是没有角色guest [administrator]root@014faa4cba72:/# rabbitmqctl set_user_tags admin administrator #给admin用户设置管理员权限# rabbitmqctl delete_user admin # 删除admin用户# rabbitmqctl stop_app # 停滞rabbitmq做事# rabbitmqctl stop # 会将rabbitmq的做事和erlang虚拟机一同关闭再次利用admin用户就可以登录web管理系统了。在其他的rabbitmq中也创建用户,以便后期可以访问后端管理系统。
配置集群1、同步cookie集群中的Rabbitmq节点须要通过交流密钥令牌以得到相互认证,如果节点的密钥令牌不一致,那么在配置节点时就会报错。获取某一个节点上的/var/lib/rabbitmq/.erlang.cookie文件,然后将其复制到其他的节点上。我们以node01节点为基准,进行此操作。
docker cprabbitmq_01:/var/lib/rabbitmq/.erlang.cookie .docker cp.erlang.cookie rabbitmq_02:/var/lib/rabbitmqdocker cp.erlang.cookie rabbitmq_03:/var/lib/rabbitmq2、建立集群关系目前3个节点都是独立的运行,之间并没有任何的关联关系。接下来我们就来建立3者之间的关联关系,我们以rabbitmq-node01为基准,将其他的两个节点加入进来。把rabbitmq-node02加入到节点1中
# 进入到rabbitmq-node02中rabbitmqctl stop_app # 关闭rabbitmq做事rabbitmqctl reset # 进行重置rabbitmqctl join_cluster rabbit@rabbitmq-node01 # rabbitmq-node01为节点1的主机名称rabbitmqctl start_app # 启动rabbitmq节点把rabbitmq-node03加入到节点1中
# 进入到rabbitmq-node03中rabbitmqctl stop_app # 关闭rabbitmq做事rabbitmqctl reset # 清空节点的状态,并将其规复都空缺状态,当设置的节点时集群中的一部分,该命令也会和集群中的磁盘节点进行通讯,见告他们该节点正在离开集群。不然集群会认为该节点处理故障,并期望其终极能够规复过来rabbitmqctl join_cluster rabbit@rabbitmq-node01 # rabbitmq-node01为节点1的主机名称rabbitmqctl start_app # 启动rabbitmq节点进入后台管理系统查看集群概述。
节点类型节点类型先容在利用rabbitmqctl cluster_status命令来查看集群状态时会有[{nodes,[{disc['rabbit@rabbitmqnode01','rabbit@rabbitmq-node02','rabbit@rabbitmq-node03']}这一项信息,个中的disc标注了Rabbitmq节点类型。Rabbitmq中的每一个节点,不管是单一节点系统或者是集群中的一部分要么是内存节点,要么是磁盘节点。内存节点将所有的行列步队,交流机,绑定关系、用户、权限和vhost的元数据定义都存储在内存中,而磁盘节点则将这些信息存储到磁盘中。单节点的集群中一定只有磁盘类型的节点,否则当重启Rabbitmq之后,所有关于系统配置信息都会丢失。不过在集群中,可以选择配置部分节点为内存节点,这样可以得到更高的性能。
节点类型变更如果我们没有指定节点类型,那么默认便是磁盘节点。我们在添加节点的时候,可以利用如下的命令来指定节点的类型为内存节点:
rabbitmqctl join_cluster rabbit@rabbitmq-node01 --ram我们也可以利用如下的命令将某一个磁盘节点设置为内存节点:
rabbitmqctl change_cluster_node_type {disc , ram}如下所示
root@rabbitmq-node02:/# rabbitmqctl stop_app # 关闭rabbitmq做事Stopping rabbit application on node 'rabbit@rabbitmq-node02'root@rabbitmq-node02:/# rabbitmqctl change_cluster_node_type ram # 将root@rabbitmq-node02节点类型切换为内存节点Turning 'rabbit@rabbitmq-node02'into a ram noderoot@rabbitmq-node02:/# rabbitmqctl start_app # 启动rabbitmq做事Starting node 'rabbit@rabbitmq-node02'root@rabbitmq-node02:/# rabbitmqctl cluster_status # 查看集群状态Cluster status of node 'rabbit@rabbitmq-node02'[{nodes,[{disc,['rabbit@rabbitmq-node03','rabbit@rabbitmq-node01']}, {ram,['rabbit@rabbitmq-node02']}]},{running_nodes,['rabbit@rabbitmq-node01','rabbit@rabbitmq-node03', 'rabbit@rabbitmq-node02']},{cluster_name,<<"rabbit@rabbitmq-node01">>},{partitions,[]},{alarms,[{'rabbit@rabbitmq-node01',[]}, {'rabbit@rabbitmq-node03',[]}, {'rabbit@rabbitmq-node02',[]}]}]root@rabbitmq-node02:/#节点选择
Rabbitmq只哀求在集群中至少有一个磁盘节点,其他所有的节点可以是内存节点。当节点加入或者离开集群时,它们必须将变更关照到至少一个磁盘节点。如果只有一个磁盘节点,而且不凑巧它刚好崩溃了,那么集群可以连续吸收和发送。
但是不能实行创建行列步队,交流机,绑定关系、用户已经变动权限、添加和删除集群节点操作了。也便是说、如果集群中唯一的磁盘节点崩溃了,集群仍旧可以保持运行,但是知道将该节点规复到集群前,你无法变动任何东西,以是在创建集群的时候该当担保至少有两个或者多个磁盘节点。
当内存节点重启后,它会连接到预先配置的磁盘节点,下载当前集群元数据的副本。当在集群中添加内存节点的时候,确保奉告所有的磁盘节点(内存节点唯一存储到磁盘中的元数据信息是磁盘节点的地址)。只要内存节点可以找到集群中至少一个磁盘节点,那么它就能在重启后重新加入集群中。
10.2 集群优化:HAproxy负载+Keepalived高可用之前搭建的集群存在的问题:不具有负载均衡能力
本次我们所选择的负载均衡层的软件是HAProxy。为了担保负载均衡层的高可用,我们须要利用利用到keepalived软件,利用vrrp协议产生虚拟ip实现动态的ip洒脱。
keepalived因此VRRP协议为实现根本的,VRRP全称Virtual Router Redundancy Protocol,即虚拟路由冗余协议。虚拟路由冗余协议,可以认为是实现路由器高可用的协议,即将N台供应相同功能的路由器组成一个路由器组,这个组里面有一个master和多个backup,master上面有一个对外供应做事的vip(该路由器所在局域网内其他机器的默认路由为该vip),master会定义向backup发送vrrp协议数据包,当backup收不到vrrp包时就认为master宕掉了,这时就须要根据VRRP的优先级来选举一个backup当master。这样的话就可以担保路由器的高可用了。优化实现在两个内存节点上安装HAProxy
yum install haproxy编辑配置文件
vim /etc/haproxy/haproxy.cfgglobal log 127.0.0.1 local2 chroot /var/lib/haproxy pidfile /var/run/haproxy.pid maxconn 4000 user haproxy group haproxy daemon stats socket /var/lib/haproxy/statsdefaults log global option dontlognull option redispatch retries 3 timeout connect 10s timeout client 1m timeout server 1m maxconn 3000listen http_front mode http bind 0.0.0.0:1080 #监听端口 stats refresh 30s #统计页面自动刷新韶光 stats uri /haproxy?stats #统计页面url stats realm Haproxy Manager #统计页面密码框上提示文本 stats auth admin:123456 #统计页面用户名和密码设置listen rabbitmq_admin bind 0.0.0.0:15673 server node1 192.168.8.40:15672 server node2 192.168.8.45:15672listen rabbitmq_cluster 0.0.0.0:5673 mode tcp balance roundrobin timeout client 3h timeout server 3h timeout connect 3h server node1 192.168.8.40:5672 check inter 5s rise 2 fall 3 server node2 192.168.8.45:5672 check inter 5s rise 2 fall 3启动HAproxy
haproxy -f /etc/haproxy/haproxy.cfg安装keepalived
yum -y install keepalived修正配置文件
vim /etc/keepalived/keepalived.confglobal_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 192.168.200.1 smtp_connect_timeout 30 router_id LVS_DEVEL vrrp_skip_check_adv_addr # vrrp_strict # 注释掉,不然访问不到VIP vrrp_garp_interval 0 vrrp_gna_interval 0}global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 192.168.200.1 smtp_connect_timeout 30 router_id LVS_DEVEL vrrp_skip_check_adv_addr # vrrp_strict # 注释掉,不然访问不到VIP vrrp_garp_interval 0 vrrp_gna_interval 0}# 检测任务vrrp_script check_haproxy { # 检测HAProxy监本 script "/etc/keepalived/script/check_haproxy.sh" # 每隔两秒检测 interval 2 # 权重 weight 2}# 虚拟组vrrp_instance haproxy { state MASTER # 此处为`主`,备机是 `BACKUP` interface ens33 # 物理网卡,根据情形而定 mcast_src_ip 192.168.8.40 # 当前主机ip virtual_router_id 51 # 虚拟路由id,同一个组内须要相同 priority 100 # 主机的优先权要比备机高 advert_int 1 # 心跳检讨频率,单位:秒 authentication { # 认证,组内的要相同 auth_type PASS auth_pass 1111 } # 调用脚本 track_script { check_haproxy } # 虚拟ip,多个换行 virtual_ipaddress { 192.168.8.201 }}启动
keepalived -D10.3 RabbitMQ镜像行列步队1、为什么要存在镜像行列步队为了担保行列步队和的高可用2、什么是镜像行列步队,镜像行列步队是如何进行选取主节点的?引入镜像行列步队的机制,可以将行列步队镜像到集群中的其他的Broker节点之上,如果集群中的一个节点失落效了,行列步队能自动的切换到镜像中的另一个节点之上以担保做事的可用性。在常日的用法中,针对每一个配置镜像的行列步队(一下称之为镜像行列步队)都包含一个主节点(master)和多少个从节点(slave),如下图所示:
集群办法下,行列步队和是无法在节点之间同步的,因此须要利用RabbitMQ的镜像行列步队机制进行同步。
深入理解参考文章:https://blog.csdn.net/u013256816/article/details/71097186
11 RabbitMQ的运用笔者就职于电商公司,就以电商秒杀场景为背景,阐述下RabbitMQ的实践。
11.1 场景:订单未支付库存回退当用户秒杀成功往后,就须要勾引用户去订单页面进行支付。如果用户在规定的韶光之内(30分钟),没有完成订单的支付,此时我们就须要进行库存的回退操作。
架构图详细实现便是利用的去世信行列步队,可以参考上面的代码。
11.2 场景:RabbitMQ秒杀公正性担保的可靠性传输可以担保秒杀业务的公正性。关于秒杀业务的公正性,我们还须要考虑一点:的顺序性(前辈入行列步队的前辈行处理)
RabbitMQ顺序性解释
顺序性:的顺序性是指消费者消费到的和发送者发布的的顺序是同等的。举个例子,不考虑重复的情形,如果生产者发布的分别为msgl、msg2、msg3,那么消费者一定也是按照msgl、msg2、msg3的顺序进行消费的。
目前很多资料显示RabbitMQ的能够保障顺序性,这是禁绝确的,或者说这个不雅观点有很大的局限性。在不该用任何RabbitMQ的高等特性,也没有丢失、网络故障之类非常的情形发生,并且只有一个消费者的情形下,也只有一个生产者的情形下可以担保的顺序性。如果有多个生产者同时发送,无法确定到达Broker 的前后顺序,也就无法验证的顺序性,由于每一次的发送都是在各自的线程中进行的。
RabbitMQ顺序错乱演示
生产者发送:1、不该用生产者确认机制,单生产者单消费者可以担保的顺序性2、利用了生产者确认机制,那么就无法担保到达Broker的前后顺序,由于的发送是异步发送的,每一个线程的实行韶光不同3、生产端利用事务机制,担保的顺序性
消费端消费:1、单消费者可以担保的顺序性2、多消费者不能担保的顺序,由于每一个的消费都是在各自的线程中进行,每一个线程的实行韶光不同
RabbitMQ顺序性保障生产端启用事务机制,单生产者单消费者。如果我们不考虑到达MQ的顺序,只是考虑对已经到达到MQ中的顺序消费,那么须要担保消费者是单消费者即可。
11.3 场景:RabbitMQ秒杀不超卖担保要担保秒杀不超卖,我们须要在很多的环节进行考虑。比如:在进行预扣库存的时候,我们须要考虑不能超卖,在进行数据库真实库存扣减的时候也须要考虑不能超卖。而对我们的mq这个环节而言,要担保不超卖我们只须要担保不被重复消费。
首先我们可以确认的是,触发重复实行的条件会是很苛刻的!
幂等性保障方案
也就说 在大多数场景下不会触发该条件!
!
!
一样平常出在任务超时,或者没有及时返回状态,引叛逆务重新入行列步队,由于做事端没有收到消费真个ack应答,因此该条还会重新进行投递。重复消费不可怕,恐怖的是你没考虑到重复消费之后,怎么担保幂等性。所谓幂等性,便是对接口的多次调用所产生的结果和调用一次是同等的。普通点说,就一个数据,或者一个要求,给你重复来多次,你得确保对应的数据是不会改变的,不能出错。举个例子:假设你有个别系,消费一条就往数据库里插入一条数据,假如你一个重复消费两次,你不就插入了两条,这数据不就错了?但是你假如消费到第二次的时候,自己判断一下是否已经消费过了,若是就直接扔了,这样不就保留了一条数据,从而担保了数据的精确性。一条数据重复消费两次,数据库里就只有一条数据,这就担保了系统的幂等性。怎么担保行列步队消费的幂等性?这一点须要结合的实际的业务来进行处理:1、比如我们消费的数据须要写数据库,你先根据主键查一下,如果这数据都有了,你就别插入了,实行以下update操作2、比如我们消费的数据须要写Redis,那没问题了,反正每次都是set,天然幂等性。3、比如你不是上面两个场景,那做的轻微繁芜一点,你须要让生产者发送每条数据的时候,里面加一个全局唯一的id,类似订单id 之类的东西,然后你这里消费到了之后,先根据这个id 去比如Redis 里查一下,之前消费过吗?如果没有消费过,你就处理,然后这个id 写Redis。如果消费过了,那你就别处理了,担保别重复处理相同的即可。4、比如基于数据库的唯一键来担保重复数据不会重复插入多条。由于有唯一键约束了,重复数据插入只会报错,不会导致数据库中涌现脏数据。
12 口试题1、行列步队的浸染与利用场景?2、创建行列步队和交流机的方法?3、多个消费者监听一个生产者时,如何分发?4、无法被路由的,去了哪里?5、在什么时候会变成Dead Letter(去世信)?6、RabbitMQ如何实现延迟行列步队?7、如何担保的可靠性投递?8、如何在做事端和消费端做限流?9、如何担保的顺序性?10、RabbitMQ的节点类型?11、...推举学习1:中间件合集:MQ(ActiveMQ/RabbitMQ/RocketMQ)+Kafka+条记
推举学习2:数据库中间件:Mycat 威信指南+Mycat 实战条记,左右开弓
推举学习3:“68道 Redis+168道 MySQL”佳构口试题(带解析),你背废了吗?