
文章目录
[+]
我们来复习下
group by 含义by后面跟指定的规则对数据进行分组,分组便是将一个“数据集”根据条件拆分多少“小数据集”,然后针对“小数据集”进行数据处理。

(图片来自网络侵删)
distinct 可以去重,实在group by 也是自带去重效果的
如下我根据条件(部门)去重,我看了下默认是每个部门的第一条数据
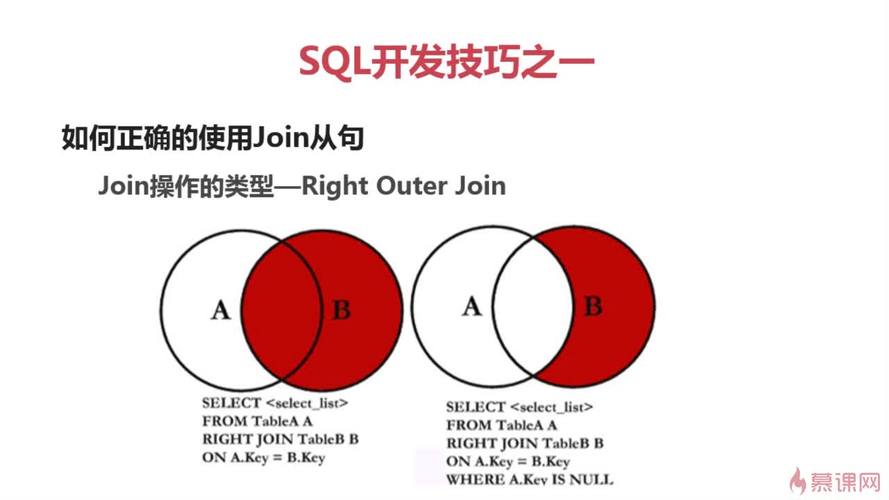
实际业务一样平常分组都会合营聚合函数利用
用法2(合营聚合函数)
合营聚合函数一起打算
常见的5个聚合函数sum,max,min,avg,count
统计每个部门人为最高的结果
用法3(合营HAVING)求每部门最高人为的员工group by 合营max能轻松求出每部门最高人为,
但是求最高人为的员工信息就须要2张表关联查询了
小白们牢记不要以为这个SQL便是终极精确结果
除了salary、dept部门是精确的,其他字段是分组前默认第一条数据,
以是如果你是顺序插入,到可以根据实际业务去1条SQL搞定(不推举)。
精确写法join
join写法性能最佳
实际业务这个 dept必须是索引才可以
查单张表求最大人为方法
这里我是根据人为从大到小顺序插入的,
group by 后查出来的便是最大人为(默认第一条数据)
group by 字段 ORDER BY null
order by null真可以提升性能,请见如下MySQL实行操持
group by 总结1 group by返回的数据是有序的,如果不想排序摧残浪费蹂躏资源可往后面跟 ORDER BY null,实行操持可能会少一个Using filesortselect 行(原则上只能是分组列或函数列),但由于版本问题,可能会输出第一行的其他字段数据合营聚合函数统计出来的
编程、后端开拓、口试的程序员、数据库、打算机软件、MySQL
以上皆为个人理解,如果有理解错的地方,欢迎专家指出














