
“字节跳动根本架构实践”系列文章是由字节跳动根本架构部门各技能团队及专家倾力打造的技能干货内容,和大家分享团队在根本架组成长和演进过程中的实践履历与教训,与各位技能同学一起互换发展。
coredump 我们日常开拓中常常会碰着,能够帮助我们赞助定位问题,但如果 coredump 涌现 truncate 会给排查问题带来不便。本文以线上问题为例,借助这个Case我们深入理解一下这类问题的排查思路,以及如何利用一些调试工具、阅读内核源代码,更清晰地理解coredump的处理过程。希望能为大家在排查这类问题的时候,供应一个清晰的脉络。

在 c/cpp 类的程序开拓中进程碰着 coredump,偶尔会碰着 coredump truncate 问题,影响 core 后的问题排查。coredump truncate 大部分是由于 core limits 和剩余磁盘空间引发的。这种比较好排查和解决。本日我们要剖析的一种分外的 case。
借助这个 Case 我们深入理解一下这类问题的排查思路,利用一些调试工具和阅读内核源代码能更清晰的理解 coredump 的处理过程。能够在排查这类问题的时候有个清晰的脉络。
业务同学反馈在容器内的做事出 core 后 gdb 调试报错。业务的做事运行在 K8S+Docker 的环境下,做事在容器内终极由 system 托管。 在部分机器上的 coredump 文件在 gdb 的时候涌现如下警告,导致排查问题受影响。报错信息如下:
BFD:Warning:/tmp/coredump.1582242674.3907019.dp-b9870a84ea-867bccccdd-5hb7histruncated:expectedcorefilesize>=89036038144,found:31395205120.
导致的结果是 gdb 无法连续调试。我们登录机器后排查不是磁盘空间和 core ulimit 的问题。须要进一步排查。
名词约定:GDB:UNIX 及 UNIX-like 下的二进制调试工具,
Coredump: 核心转储,是操作系统在进程收到某些旗子暗记而终止运行时,将此时进程地址空间的内容以及有关进程状态的其他信息写出的一个磁盘文件。这种信息每每用于调试。
ELF: 可实行与可链接格式(Executable and Linkable Format),用于可实行文件、目标文件、共享库和核心转储的标准文件格式。x86 架构上的类 Unix 操作系统的二进制文件格式标准。
BFD: 二进制文件描述库(Binary File Descriptor library)是 GNU 项目用于办理不同格式的目标文件的可移植性的紧张机制。
VMA: 虚拟内存区域(Virtual Memory Area),VMA 是用户进程里的一段 virtual address space 区块,内核利用 VMA 来跟踪进程的内存映射。
排查过程用户态排查开始疑惑是自研的 coredump handler 程序有问题。于是还原系统原来的 coredump。
手动触发一次 Coredump。结果问题依然存在。 现在打消 coredump handler 的问题。解释问题可能发生在 kernel 层或 gdb 的问题。
须要确定是 gdb 问题还是 kernel 吐 core 的问题。 先从 gdb 开始查起,下载 gdb 的源代码找到报错的位置(为了方便阅读,源代码的缩进进行了调度)。
目前看不是 gdb 的问题。coredump 文件写入不完全。coredump 的写入是由内核完成的。须要从内核侧排查。
在排查之前不雅观察这个 coredump 的程序利用的内存利用非常大,几十 G 规模。疑惑是否和其过大有关,于是做一个实验。写一个 50G 内存的程序仿照,并对其 coredump。
#include<unistd.h>#include<stdlib.h>#include<string.h>intmain(void){for(inti=0;i<1024;i++){voidtest=malloc(1024102450);//50MBmemset(test,0,1);}sleep(3600);}
经由测试正常吐 core。gdb 正常,暂时打消 core 大体积问题。
以是初步判断是 kernel 在吐的 core 文件自身的问题。须要在进一步跟进。
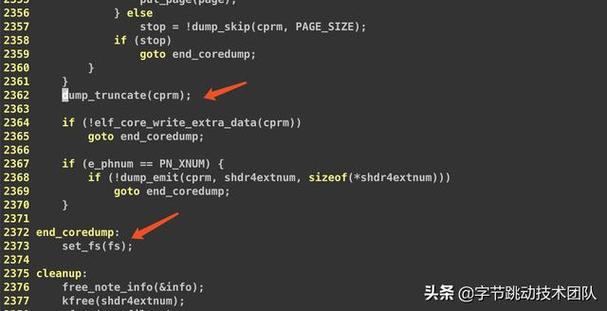
查看内核代码创造一处可疑点:
/Ensuresthatfilesizeisbigenoughtocontainthecurrentfilepostion.Thispreventsgdbfromcomplainingaboutatruncatedfileifthelast"write"tothefilewasdump_skip./voiddump_truncate(structcoredump_paramscprm){structfilefile=cprm->file;loff_toffset;if(file->f_op->llseek&&file->f_op->llseek!=no_llseek){offset=file->f_op->llseek(file,0,SEEK_CUR);if(i_size_read(file->f_mapping->host)<offset)do_truncate(file->f_path.dentry,offset,0,file);}}
这段代码的注释引起了我们的把稳。
现在疑惑在涌现这个 case 的时候没有实行到这个 dump_truncate 函数。于是考试测验把 dump_truncate 移到第二个位置处。重新编译内核考试测验。 重新打了测试内核测试后问题依然存在。
于是连续看代码:
这段代引起了把稳。疑惑某个时候实行 get_dump_page 的时候返回了 NULL。然后走到了 dump_skip 函数,dump_skip 返回 0,导致 goto end_coredump。于是 stap 抓下。
不出所料,dump_skip 返回 0 后 coredump 停滞。也便是说第二阶段只 dump 了一部分 vma 就停滞了。 导致 coredump 写入不完全。
VMA 部分 dump 剖析再看下 dump_skip 函数:
intdump_skip(structcoredump_paramscprm,size_tnr){staticcharzeroes[PAGE_SIZE];structfilefile=cprm->file;if(file->f_op->llseek&&file->f_op->llseek!=no_llseek){if(dump_interrupted()||file->f_op->llseek(file,nr,SEEK_CUR)<0)return0;cprm->pos+=nr;return1;}else{while(nr>PAGE_SIZE){if(!dump_emit(cprm,zeroes,PAGE_SIZE))return0;nr-=PAGE_SIZE;}returndump_emit(cprm,zeroes,nr);}}
由于 coredump 是 pipe 的,所以是没有 llseek 操作的,因此会走到 else 分支里。也便是 dump_emit 返回 0 导致的。于是 stap 抓下 dump_emit 函数:
functionfunc:string(task:long)%{snprintf(STAP_RETVALUE,MAXSTRINGLEN,"%s",signal_pending(current)?"true":"false");%}probekernel.function("dump_emit").return{printf("return:%d,cprm->limit:%d,cprm->written:%d,signal:%s\n",$return,@entry($cprm->limit),@entry($cprm->written),func($return));}
结果如下:
return:1,cprm->limit:-1,cprm->written:0,signal:falsereturn:1,cprm->limit:-1,cprm->written:64,signal:falsereturn:1,cprm->limit:-1,cprm->written:120,signal:false...省略9221238行...return:1,cprm->limit:-1,cprm->written:37623402496,signal:falsereturn:1,cprm->limit:-1,cprm->written:37623406592,signal:falsereturn:1,cprm->limit:-1,cprm->written:37623410688,signal:falsereturn:0,cprm->limit:-1,cprm->written:37623414784,signal:true
不出意外和疑惑的同等,dump_emit 返回 0 了,此时写入到 core 文件的有 37623414784 字节。紧张由于 dump_interrupted 检测条件为真。(cprm->limit = -1 不会进入 if 逻辑,kernrel_wirte 写 pipe 也没有出错)。
下面我们看 dump_interrupted 函数。为了方便阅读,整理出干系的函数:
staticbooldump_interrupted(void){/SIGKILLorfreezing()interruptthecoredumping.Perhapswecandotry_to_freeze()andcheck__fatal_signal_pending(),butthenweneedtoteachdump_write()torestartandclearTIF_SIGPENDING./returnsignal_pending(current);}staticinlineintsignal_pending(structtask_structp){returnunlikely(test_tsk_thread_flag(p,TIF_SIGPENDING));}staticinlineinttest_tsk_thread_flag(structtask_structtsk,intflag){returntest_ti_thread_flag(task_thread_info(tsk),flag);}staticinlineinttest_ti_thread_flag(structthread_infoti,intflag){returntest_bit(flag,(unsignedlong)&ti->flags);}/test_bit-Determinewhetherabitisset@nr:bitnumbertotest@addr:Addresstostartcountingfrom/staticinlineinttest_bit(intnr,constvolatileunsignedlongaddr){return1UL&(addr[BIT_WORD(nr)]>>(nr&(BITS_PER_LONG-1)));}
干系的宏:
#ifdef CONFIG_64BIT#define BITS_PER_LONG 64#else#define BITS_PER_LONG 32#endif / CONFIG_64BIT /#define TIF_SIGPENDING 2 / signal pending / 平台干系。以X64架构为例。
有上面的代码就很清楚 dump_interrupted 函数便是检测 task 的 thread_info->flags 是否 TIF_SIGPENDING 置位。
目前疑惑还是和用户的内存 vma 有关。但什么场景会触发 TIF_SIGPENDING 置位是个问题。dump_interrupted 函数的注释中已经解释了,一个是吸收到了 KILL 旗子暗记,一个是 freezing()。 freezing()一样平常和 cgroup 有关,一样平常是 docker 在利用。KILL 有可能是 systemd 发出的。 于是做了 2 个实验:
实验一:systemd启动实例,bash裸起做事,不接流量。测试结果gdb正常...然后再用systemd起来,不接流量。测试结果也是正常的。这就奇怪了。但是不能打消systemd。回忆接流量和不接流量的差异是coredump的压缩后的体历年夜小不同,不接流量vma大都是空,空洞比较多,因此coredump非常快,有流量vma不是空的,coredump比较慢。因此疑惑和coredump韶光有关系,超过某个韶光就有TIF_SIGPENDING被置位。实验二:
是产生一个50G的内存。代码如最上方。在容器内依然利用systemd启动一个测试程序(直接在问题容器内更换这个bin。然后systemctl重启做事)然后发送SEGV旗子暗记。stap抓一下。coredump很漫长。等待结果结果很意外。core正常,gdb也正常。
这个 TIF_SIGPENDING 旗子暗记源是个问题。
还有个排查方向便是 get_dump_page 为啥会返回 NULL。 以是现在有 2 个排查方向:
须要确定 TIF_SIGPENDING 旗子暗记源。get_dump_page 返回 NULL 的缘故原由。get_dump_page 返回 NULL 剖析首先看 get_dump_page 这个返回 NULL 的 case:
ReturnsNULLonanykindoffailure-aholemustthenbeinsertedintothecorefile,topreservealignmentwithitsheaders;andalsoreturnsNULLwherevertheZERO_PAGE,orananonymouspte_none,hasbeenfound-allowingaholetobeleftinthecorefiletosavediskspace.
看注释返回 NULL,一个是 page 是 ZERO_PAGE,一个是 pte_none 问题。
首先看 ZREO 问题,于是布局一个 ZERO_PAGE 的程序来测试:
#include<stdio.h>#include<unistd.h>#include<sys/mman.h>constintBUFFER_SIZE=40961000;intmain(void){inti=0;unsignedcharbuffer;for(intn=0;n<10240;n++){buffer=mmap(NULL,BUFFER_SIZE,PROT_READ|PROT_WRITE,MAP_PRIVATE|MAP_ANONYMOUS,-1,0);for(i=0;i<BUFFER_SIZE-34096;i+=4096){buffer[i]=0;}}//zeropagefor(i=0;i<BUFFER_SIZE-4096;i+=4096){chardirty=buffer[i];printf("%c",dirty);}printf("ok...\n");sleep(3600);}
测试结果是 coredump 正常,同时 trace 一下 get_dump_page 的返回值。 结果和预想的有些不同,返回了很多个 NULL。 解释和 get_dump_page 函数的成分不大。
于是转向到 TIF_SIGPENDING 旗子暗记发生源。
TIF_SIGPENDING 旗子暗记来源剖析bpftrace 抓一下看看:
#!/usr/bin/envbpftrace#include<linux/sched.h>kprobe:__send_signal{$t=(structtask_struct)arg2;if($t->pid==$1){printf("comm:%s(pid:%d)sendsig:%dto%s\n",comm,pid,arg0,$t->comm);}}
结果如下:
结果比较有趣。kill 和 systemd 打断了 coredump 进程。旗子暗记 2(SIGINT)和旗子暗记 9(SIGKILL)都足以打断进程。 现在问题变为 kill 和 systemd 为什么会发送这 2 个旗子暗记。一个疑惑是超时。coredump 进程为 not running 太久会不会触发 systemd 什么机制呢。
于是查看了 systemd service 的 doc 创造这样一段话:
TimeoutAbortSec=This option configures the time to wait for the service to terminate when it was aborted due to a watchdog timeout (see WatchdogSec=). If the service has a short TimeoutStopSec= this option can be used to give the system more time to write a core dump of the service. Upon expiration the service will be forcibly terminated by SIGKILL (see KillMode= in systemd.kill(5)). The core file will be truncated in this case. Use TimeoutAbortSec= to set a sensible timeout for the core dumping per service that is large enough to write all expected data while also being short enough to handle the service failure in due time.Takes a unit-less value in seconds, or a time span value such as "5min 20s". Pass an empty value to skip the dedicated watchdog abort timeout handling and fall back TimeoutStopSec=. Pass "infinity" to disable the timeout logic. Defaults to DefaultTimeoutAbortSec= from the manager configuration file (see systemd-system.conf(5)).If a service of Type=notify handles SIGABRT itself (instead of relying on the kernel to write a core dump) it can send "EXTEND_TIMEOUT_USEC=…" to extended the abort time beyond TimeoutAbortSec=. The first receipt of this message must occur before TimeoutAbortSec= is exceeded, and once the abort time has exended beyond TimeoutAbortSec=, the service manager will allow the service to continue to abort, provided the service repeats "EXTEND_TIMEOUT_USEC=…" within the interval specified, or terminates itself (see sd_notify(3)).
标红的字引起了把稳,于是调大一下(TimeoutAbortSec="10min")再试。无效...
无效后就很奇怪,难道 system 都不是旗子暗记的发起者,是旗子暗记的"通报者"? 现在有 2 个疑惑,一个是 systemd 是旗子暗记的发起者,一个是 systemd 不是旗子暗记的发起者,是旗子暗记的“通报者”。于是这次同时抓业务进程和 systemd 进程看看。 结果如下:
个中 3533840 是容器的 init 进程 systemd。3533916 是业务进程。和预想的一样,systemd 并不是旗子暗记的第一个发起者。systemd 是吸收到 runc 的旗子暗记 15(SIGTERM)而停滞的,停滞前会对子进程发起 kill 行为。也便是末了的 systemd send sig。
有个疑问就来了,之前用程序 1 测试了 system+docker 的场景,没有复现,回忆一下 coredump 的过程该当是这样的,程序 1 没有对每个 page 都写,只写了一个 malloc 之后的第一个 page 的第一个一个字节。coredump 在遍历每个 vma 的时候耗时要比都写了 page 要快很多(由于没有那么多空洞,VMA 不会那么零星)。coredump 体积虽然大,但韶光短,因此没有触发这个问题,对付排查这个问题带来一定的弯曲。
于是排查方向转到 kill 命令和 runc。 经由排查创造 K8S 的一个 lifecycle 中的 prestop 脚本有 kill 行为。 把这个脚本停到后再次抓一下:
这次没有 kill 行为,但是 systemd 还是被 runc 杀去世了,发送了 2 个旗子暗记,一个是 SIGTERM,一个是 SIGKILL。 现在阐明通了 kill 旗子暗记的来源,这也就阐明了 kill 的旗子暗记来源。实在 kill 和 systemd 的旗子暗记根源间接或直接都是 runc。runc 的销毁指令来自 k8s。
于是根据 K8S 的日志连续排查。经由排查创造终极的触发逻辑是来自字节内部实现的 Load 驱逐。该机制当容器的 Load 过高时则会把这个实例驱逐掉,避免影响其他实例。 由于 coredump 的时候 CPU 会长期陷入到内核态,导致 load 升高。以是 I 引发了 Pod 驱逐。
coredump 期间实例的负载很高,导致 k8s 的组件 kubelet 的触发了 load 高驱逐实例的行为。删除 pod。停滞 systemd。杀去世正在 coredump 的进程,终极导致 coredump 第二阶段写 vma 数据未完成。
验证问题在做一个大略的验证,停滞 K8S 组件 kubelet,然后对做事发起 core。末了 gdb。 验证正常,gdb 正常读取数据。 至此这个问题就排查完毕了。 末了修正内部实现 cgroup 级的 Load(和整机 load 近似的采集数据的方案)采集功能,过滤 D 状态的进程(coredump 进程在用户态表现为 D 状态)后,这个问题彻底办理。
总结本次 coredump 文件 truncate 是由于 coredump 的进程被杀去世(SIGKILL 旗子暗记)导致 VMA 没有写入完备(只写入了一部分)导致,。 办理这个问题通过阅读内核源代码加以利用 bpftrace、systemtap 工具追踪 coredump 的过程。打印出关心的数据,借助源代码终极剖析出问题的缘故原由。同时我们对内核的 coredump 过程有了一定的理解。
末了,欢迎加入字节跳动根本架构团队,一起磋商、办理问题,一起变强!
附:coredump 文件大略剖析
在排查这个问题期间也阅读了内核处理 coredump 的干系源代码,大略总结一下:
coredump 文件实在是一个精简版的 ELF 文件。coredump 过程并不繁芜。 coredump 的过程分为 2 个阶段,一个阶段是写 program header(第一个 program header 是 Note Program Header),每个 program header 包含了 VMA 的大小和在文件的偏移量。gdb 也是依此来确定每个 VMA 的位置的。另一个阶段是写 vma 的数据,遍历进程的所有 vma。然后写入文件。 一个 coredump 文件的构造可以大略的用如下图的构造表示。
参考文献Binary_File_Descriptor_librarysystemd.service — Service unit configurationKubernets Pod Lifecycle更多分享
字节跳动在 RocksDB 存储引擎上的改进实践
字节跳动自研万亿级图数据库&图打算实践
深入理解 Linux 内核--jemalloc 引起的 TLB shootdown 及优化
字节跳动根本架构团队字节跳动根本架构团队是支撑字节跳动旗下包括抖音、今日头条、西瓜视频、火山小视频在内的多款亿级规模用户产品平稳运行的主要团队,为字节跳动及旗下业务的快速稳定发展供应了担保和推动力。
公司内,根本架构团队紧张卖力字节跳动私有云培植,管理恒河沙数做事器规模的集群,卖力数万台打算/存储稠浊支配和在线/离线稠浊支配,支持多少 EB 海量数据的稳定存储。
文化上,团队积极拥抱开源和创新的软硬件架构。我们长期招聘根本架构方向的同学,详细可拜会 job.bytedance.com (文末“阅读原文”),感兴趣可以联系邮箱 guoxinyu.0372@bytedance.com。
欢迎关注字节跳动技能团队















