
2)JMS连接。JMS连接(Connection)表示JMS客户端和做事器端之间的一个活动的连接,是由客户端通过调用连接工厂的方法建立的。
3)JMS会话。JMS会话(Session)表示JMS客户与JMS做事器之间的会话状态。JMS会话建立在JMS连接上,表示客户与做事器之间的一个会话线程。

4)JMS目的。JMS目的(Destination),又称为行列步队,是实际的源。
5)JMS生产者和消费者。生产者(Message Producer)和消费者(Message Consumer)工具由Session工具创建,用于发送和吸收。
6)JMS常日有两种类型:
① 点对点(Point-to-Point)。在点对点的系统中,分发给一个单独的利用者。点对点每每与行列步队(javax.jms.Queue)干系联。
② 发布/订阅(Publish/Subscribe)。发布/订阅系统支持一个事宜驱动模型,生产者和消费者都参与的通报。生产者发布事宜,而利用者订阅感兴趣的事宜,并利用事宜。该类型一样平常与特定的主题(javax.jms.Topic)关联。
06 安装ActiveMQ
windows安装
下载地址:http://activemq.apache.org/activemq-5150-release.html
下载完成后解压进入bin目录 运行 activemq.bat。
如果你碰着如下问题,5672端口被占用
可以去修正activemq的conf目录下的activemq.xml,把amqp的端口改为其他的,这里改成了5673
再次启动:
访问地址:http://127.0.0.1:8161/admin/进入后台页面 初始账号密码 admin admin
Docker安装ActiveMQ
docker run -d --name activemq -p 61616:61616 -p 8161:8161 webcenter/activemq
07 ActiveMQ快速入门Springboot集成ActiveMQ
导入依赖
<dependencies> <!--Springboot--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> <version>2.3.0.RELEASE</version> </dependency> <!--ActiveMq--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-activemq</artifactId> <version>1.5.0.RELEASE</version> </dependency> <!--行列步队连接池--> <dependency> <groupId>org.apache.activemq</groupId> <artifactId>activemq-pool</artifactId> <version>5.15.0</version> </dependency> </dependencies>
配置MQ
server: port: 8080spring: activemq: broker-url: tcp://127.0.0.1:61616 user: admin password: admin close-timeout: 15s # 在考虑结束之前等待的韶光 in-memory: true # 默认代理URL是否该当在内存中。如果指定了显式代理,则忽略此值。 non-blocking-redelivery: false # 是否在回滚回滚之前停滞通报。这意味着当启用此命令时,顺序不会被保留。 send-timeout: 0 # 等待发送相应的韶光。设置为0等待永久。 queue-name: active.queue topic-name: active.topic.name.model # packages: # trust-all: true #不配置此项,会报错 pool: enabled: true max-connections: 10 #连接池最大连接数 idle-timeout: 30000 #空闲的连接过期韶光,默认为30秒 # jms: # pub-sub-domain: true #默认情形下activemq供应的是queue模式,若要利用topic模式须要配置下面配置# 是否信赖所有包#spring.activemq.packages.trust-all=# 要信赖的特定包的逗号分隔列表(当不信赖所有包时)#spring.activemq.packages.trusted=# 当连接要乞降池满时是否壅塞。设置false会抛“JMSException非常”。#spring.activemq.pool.block-if-full=true# 如果池仍旧满,则在抛出非常前壅塞韶光。#spring.activemq.pool.block-if-full-timeout=-1ms# 是否在启动时创建连接。可以在启动时用于加热池。#spring.activemq.pool.create-connection-on-startup=true# 是否用Pooledconnectionfactory代替普通的ConnectionFactory。#spring.activemq.pool.enabled=false# 连接过期超时。#spring.activemq.pool.expiry-timeout=0ms# 连接空闲超时#spring.activemq.pool.idle-timeout=30s# 连接池最大连接数#spring.activemq.pool.max-connections=1# 每个连接的有效会话的最大数目。#spring.activemq.pool.maximum-active-session-per-connection=500# 当有"JMSException"时考试测验重新连接#spring.activemq.pool.reconnect-on-exception=true# 在空闲连接打消线程之间运行的韶光。当为负数时,没有空闲连接驱逐线程运行。#spring.activemq.pool.time-between-expiration-check=-1ms# 是否只利用一个MessageProducer#spring.activemq.pool.use-anonymous-producers=true
编写配置类
/ @author 原 @date 2020/12/16 @since 1.0 /@Configurationpublic class BeanConfig { @Value("${spring.activemq.broker-url}") private String brokerUrl; @Value("${spring.activemq.user}") private String username; @Value("${spring.activemq.topic-name}") private String password; @Value("${spring.activemq.queue-name}") private String queueName; @Value("${spring.activemq.topic-name}") private String topicName; @Bean(name = "queue") public Queue queue() { return new ActiveMQQueue(queueName); } @Bean(name = "topic") public Topic topic() { return new ActiveMQTopic(topicName); } @Bean public ConnectionFactory connectionFactory(){ return new ActiveMQConnectionFactory(username, password, brokerUrl); } @Bean public JmsMessagingTemplate jmsMessageTemplate(){ return new JmsMessagingTemplate(connectionFactory()); } / 在Queue模式中,对的监听须要对containerFactory进行配置 @param connectionFactory @return / @Bean("queueListener") public JmsListenerContainerFactory<?> queueJmsListenerContainerFactory(ConnectionFactory connectionFactory){ SimpleJmsListenerContainerFactory factory = new SimpleJmsListenerContainerFactory(); factory.setConnectionFactory(connectionFactory); factory.setPubSubDomain(false); return factory; } / 在Topic模式中,对的监听须要对containerFactory进行配置 @param connectionFactory @return / @Bean("topicListener") public JmsListenerContainerFactory<?> topicJmsListenerContainerFactory(ConnectionFactory connectionFactory){ SimpleJmsListenerContainerFactory factory = new SimpleJmsListenerContainerFactory(); factory.setConnectionFactory(connectionFactory); factory.setPubSubDomain(true); return factory; }}
编写启动类
/ @author 原 @date 2020/12/8 @since 1.0 /@SpringBootApplication@EnableJms //开启JMS支持public class DemoApplication { @Autowired private JmsMessagingTemplate jmsMessagingTemplate; @Autowired private Queue queue; @Autowired private Topic topic; public static void main(String[] args) { SpringApplication.run(DemoApplication.class, args); } / 运用启动后,会实行该方法 会分别向queue和topic发送一条 / @PostConstruct public void sendMsg(){ jmsMessagingTemplate.convertAndSend(queue,"queue-test"); jmsMessagingTemplate.convertAndSend(topic,"topic-test"); }}
查看activemq后台
active.queue 为行列步队的名称
Number Of Pending Messages 等待消费的数量 3是由于我自己发了3次
Messages Enqueued 已经进入行列步队的数量
由于没有消费者,一贯没有被消费。下面我们编写消费者代码。
/ @author 原 @date 2020/12/16 @since 1.0 /@Componentpublic class QueueConsumerListener { @JmsListener(destination = "${spring.activemq.queue-name}",containerFactory = "queueListener") public void getQueue(String message){ System.out.println("接管queue:"+message); } @JmsListener(destination = "${spring.activemq.topic-name}",containerFactory = "topicListener") public void getTopic(String message){ System.out.println("接管topic:"+message); }}
在后台发送一条
掌握台打印
发送topic
掌握台打印:
但是创造一个问题是,之前在没有消费的时候,有3条queue和一条topic,但是当我启动消费者时,queue的3条被消费了,topic确没有。这是由于:
topic模式有普通订阅和持久化订阅
普通订阅:在消费者启动之前发送过来的,消费者启动之后不会去消费;
持久化订阅: 在消费者启动之前发送过来的,消费者启动之后会去消费;
08 ActiveMQ事理剖析同步发送与异步发送
ActiveMQ支持同步、异步两种发送模式将发送到broker上。同步发送过程中,发送者发送一条会壅塞直到broker反馈一个确认,表示已经被broker处理。这个机制供应了的安全性保障,但是由于是壅塞的操作,会影响到客户端发送的性能异步发送的过程中,发送者不须要等待broker供应反馈,以是性能相对较高。但是可能会涌现丢失的情形。以是利用异步发送的条件是在某些情形下许可涌现数据丢失的情形。默认情形下,非持久化是异步发送的,持久化并且是在非事务模式下是同步发送的。但是在开缘由务的情形下,都是异步发送。由于异步发送的效率会比同步发送性能更高。以是在发送持久化的时候,只管即便去开缘由务会话。
发送事理
ProducerWindowSize的含义
producer每发送一个,统计一下发送的字节数,当字节数达到ProducerWindowSize值时,须要等待broker的确认,才能连续发送。
代码在:ActiveMQSession的1957行紧张用来约束在异步发送时producer端许可积压的(尚未ACK)的的大小,且只对异步发送故意义。每次发送之后,都将会导致memoryUsage大小增加(+message.size),当broker返回producerAck时,memoryUsage尺寸减少(producerAck.size,此size表示先前发送的大小)。
可以通过如下2种办法设置:Ø 在brokerUrl中设置: "tcp://localhost:61616?jms.producerWindowSize=1048576",这种设置将会对所有的producer生效。Ø 在destinationUri中设置: "test-queue?producer.windowSize=1048576",此参数只会对利用此Destination实例的producer失落效,将会覆盖brokerUrl中的producerWindowSize值。
把稳:此值越大,意味着花费Client真个内存就越大。
源码剖析
ActiveMQMessageProducer.send(...)方法
public void send(Destination destination, Message message, int deliveryMode, int priority, long timeToLive, AsyncCallback onComplete) throws JMSException { checkClosed();//检讨session连接,若已关闭直接抛出非常 if (destination == null) {//校验发送的目的地是否为空,也便是必须制订queue或者topic信息 if (info.getDestination() == null) { throw new UnsupportedOperationException("A destination must be specified."); } throw new InvalidDestinationException("Don't understand null destinations"); } //这里做的是封装Destination ActiveMQDestination dest; if (destination.equals(info.getDestination())) { dest = (ActiveMQDestination)destination; } else if (info.getDestination() == null) { dest = ActiveMQDestination.transform(destination); } else { throw new UnsupportedOperationException("This producer can only send messages to: " + this.info.getDestination().getPhysicalName()); } if (dest == null) { throw new JMSException("No destination specified"); }//封装Message if (transformer != null) { Message transformedMessage = transformer.producerTransform(session, this, message); if (transformedMessage != null) { message = transformedMessage; } }//如果设置了producerWindow,则须要校验producerWindow大小 if (producerWindow != null) { try { producerWindow.waitForSpace(); } catch (InterruptedException e) { throw new JMSException("Send aborted due to thread interrupt."); } }//发送 this.session.send(this, dest, message, deliveryMode, priority, timeToLive, producerWindow, sendTimeout, onComplete);//做统计的 stats.onMessage(); }
ActiveMQSession的send方法
protected void send(ActiveMQMessageProducer producer, ActiveMQDestination destination, Message message, int deliveryMode, int priority, long timeToLive, MemoryUsage producerWindow, int sendTimeout, AsyncCallback onComplete) throws JMSException {//校验连接 checkClosed(); //校验发送目标 if (destination.isTemporary() && connection.isDeleted(destination)) { throw new InvalidDestinationException("Cannot publish to a deleted Destination: " + destination); } //互斥锁,如果一个session的多个producer发送到这里,会担保发送的有序性 synchronized (sendMutex) { // tell the Broker we are about to start a new transaction doStartTransaction(); TransactionId txid = transactionContext.getTransactionId(); long sequenceNumber = producer.getMessageSequence(); //Set the "JMS" header fields on the original message, see 1.1 spec section 3.4.11 message.setJMSDeliveryMode(deliveryMode);//设置是否持久化 long expiration = 0L; if (!producer.getDisableMessageTimestamp()) { long timeStamp = System.currentTimeMillis(); message.setJMSTimestamp(timeStamp); if (timeToLive > 0) { expiration = timeToLive + timeStamp; } } message.setJMSExpiration(expiration);//过期韶光 message.setJMSPriority(priority);//优先级 message.setJMSRedelivered(false);//是否重复发送 // transform to our own message format here 统一封装 ActiveMQMessage msg = ActiveMQMessageTransformation.transformMessage(message, connection); msg.setDestination(destination); //设置ID msg.setMessageId(new MessageId(producer.getProducerInfo().getProducerId(), sequenceNumber)); // Set the message id. if (msg != message) {//如果是经由转化的,则更新原来的id和目的地 message.setJMSMessageID(msg.getMessageId().toString()); // Make sure the JMS destination is set on the foreign messages too. message.setJMSDestination(destination); } //clear the brokerPath in case we are re-sending this message msg.setBrokerPath(null); msg.setTransactionId(txid); if (connection.isCopyMessageOnSend()) { msg = (ActiveMQMessage)msg.copy(); } msg.setConnection(connection); msg.onSend();//把属性和体都设置为只读,防止被修正 msg.setProducerId(msg.getMessageId().getProducerId()); if (LOG.isTraceEnabled()) { LOG.trace(getSessionId() + " sending message: " + msg); } //如果onComplete没有设置,且发送超时时间小于0,且不须要反馈,且连接器不是同步发送模式,且非持久化或者连接器是异步发送模式//或者存在事务id的情形下,走异步发送,否则走同步发送 if (onComplete==null && sendTimeout <= 0 && !msg.isResponseRequired() && !connection.isAlwaysSyncSend() && (!msg.isPersistent() || connection.isUseAsyncSend() || txid != null)) { this.connection.asyncSendPacket(msg); if (producerWindow != null) { // Since we defer lots of the marshaling till we hit the // wire, this might not // provide and accurate size. We may change over to doing // more aggressive marshaling, // to get more accurate sizes.. this is more important once // users start using producer window // flow control. int size = msg.getSize();//异步发送的情形下,须要设置producerWindow的大小 producerWindow.increaseUsage(size); } } else { if (sendTimeout > 0 && onComplete==null) { this.connection.syncSendPacket(msg,sendTimeout);//带超时时间的同步发送//带回调的同步发送 }else { this.connection.syncSendPacket(msg, onComplete);//带回调的同步发送 } } } }
看下异步发送的代码ActiveMQConnection. asyncSendPacket()
/ send a Packet through the Connection - for internal use only @param command @throws JMSException / public void asyncSendPacket(Command command) throws JMSException { if (isClosed()) { throw new ConnectionClosedException(); } else { doAsyncSendPacket(command); } } private void doAsyncSendPacket(Command command) throws JMSException { try { this.transport.oneway(command); } catch (IOException e) { throw JMSExceptionSupport.create(e); } }
再看看transport是个什么东西?在哪里实例化的?按照以前看源码的老例来看,它肯定不是一个纯挚的工具。按照以往我看源码的履历来看,一定是在创建连接的过程中初始化的。以是我们定位到代码
//从connection=connectionFactory.createConnection();这行代码作为入口,一贯跟踪ActiveMQConnectionFactory. createActiveMQConnection这个方法中。代码如下protected ActiveMQConnection createActiveMQConnection(String userName, String password) throwsJMSException {if (brokerURL == null) {throw new ConfigurationException("brokerURL not set.");}ActiveMQConnection connection = null;try {Transport transport = createTransport();//代码往下看connection = createActiveMQConnection(transport, factoryStats);connection.setUserName(userName);connection.setPassword(password);//省略后面的代码}
//这个方法便是实例化Transport的 1.构建Broker的URL 2.根据这个URL去创建一个链接TransportFactory.connect 默认利用的TCP连接 protected Transport createTransport() throws JMSException { try { URI connectBrokerUL = brokerURL; String scheme = brokerURL.getScheme(); if (scheme == null) { throw new IOException("Transport not scheme specified: [" + brokerURL + "]"); } if (scheme.equals("auto")) { connectBrokerUL = new URI(brokerURL.toString().replace("auto", "tcp")); } else if (scheme.equals("auto+ssl")) { connectBrokerUL = new URI(brokerURL.toString().replace("auto+ssl", "ssl")); } else if (scheme.equals("auto+nio")) { connectBrokerUL = new URI(brokerURL.toString().replace("auto+nio", "nio")); } else if (scheme.equals("auto+nio+ssl")) { connectBrokerUL = new URI(brokerURL.toString().replace("auto+nio+ssl", "nio+ssl")); } return TransportFactory.connect(connectBrokerUL);//里面的代码连续往下看 } catch (Exception e) { throw JMSExceptionSupport.create("Could not create Transport. Reason: " + e, e); } }
TransportFactory. findTransportFactory
从TRANSPORT_FACTORYS这个Map凑集中,根据scheme去得到一个TransportFactory指定的实例工具如果Map凑集中不存在,则通过TRANSPORT_FACTORY_FINDER去找一个并且构建实例Ø 这个地方又有点类似于我们之前所学过的SPI的思想吧?他会从METAINF/services/org/apache/activemq/transport/ 这个路径下,根据URI组装的scheme去找到匹配class工具并且实例化,以是根据tcp为key去对应的路径下可以找到T cpT ransportFactory //TransportFactory.connect(connectBrokerUL) public static Transport connect(URI location) throws Exception { TransportFactory tf = findTransportFactory(location); return tf.doConnect(location); } //findTransportFactory(location) public static TransportFactory findTransportFactory(URI location) throws IOException { String scheme = location.getScheme(); if (scheme == null) { throw new IOException("Transport not scheme specified: [" + location + "]"); } TransportFactory tf = TRANSPORT_FACTORYS.get(scheme); if (tf == null) { // Try to load if from a META-INF property. try { tf = (TransportFactory)TRANSPORT_FACTORY_FINDER.newInstance(scheme); TRANSPORT_FACTORYS.put(scheme, tf); } catch (Throwable e) { throw IOExceptionSupport.create("Transport scheme NOT recognized: [" + scheme + "]", e); } } return tf; }
调用TransportFactory.doConnect去构建一个连接
public Transport doConnect(URI location) throws Exception { try { Map<String, String> options = new HashMap<String, String>(URISupport.parseParameters(location)); if( !options.containsKey("wireFormat.host") ) { options.put("wireFormat.host", location.getHost()); } WireFormat wf = createWireFormat(options); Transport transport = createTransport(location, wf); Transport rc = configure(transport, wf, options); //remove auto IntrospectionSupport.extractProperties(options, "auto."); if (!options.isEmpty()) { throw new IllegalArgumentException("Invalid connect parameters: " + options); } return rc; } catch (URISyntaxException e) { throw IOExceptionSupport.create(e); } }
configure
public Transport configure(Transport transport, WireFormat wf, Map options) throws Exception { //组装一个复合的transport,这里会包装两层,一个是IactivityMonitor.另一个是WireFormatNegotiator transport = compositeConfigure(transport, wf, options); transport = new MutexTransport(transport);//再做一层包装,MutexTransport transport = new ResponseCorrelator(transport);//包装ResponseCorrelator return transport; }
到目前为止,这个transport实际上便是一个调用链了,他的链构造为ResponseCorrelator(MutexT ransport(WireFormatNegotiator(IactivityMonitor(T cpT ransport()))每一层包装表示什么意思呢?ResponseCorrelator 用于实现异步要求。MutexT ransport 实现写锁,表示同一韶光只许可发送一个要求WireFormatNegotiator 实现了客户端连接broker的时候先发送数据解析干系的协议信息,比如解析版本号,是否利用缓存等InactivityMonitor 用于实现连接成功成功后的心跳检讨机制,客户端每10s发送一次心跳信息。做事端每30s读取一次心跳信息。
同步发送和异步发送的差异
public Object request(Object command, int timeout) throws IOException {FutureResponse response = asyncRequest(command, null);return response.getResult(timeout); // 从future方法壅塞等待返回}
持久化和非持久化的存储事理
正常情形下,非持久化是存储在内存中的,持久化是存储在文件中的。能够存储的最大数据在${ActiveMQ_HOME}/conf/activemq.xml文件中的systemUsage节点SystemUsage配置设置了一些系统内存和硬盘容量
<systemUsage><systemUsage><memoryUsage>//该子标记设置全体ActiveMQ节点的“可用内存限定”。这个值不能超过ActiveMQ本身设置的最大内存大小。个中的percentOfJvmHeap属性表示百分比。占用70%的堆内存<memoryUsage percentOfJvmHeap="70" /></memoryUsage><storeUsage>//该标记设置全体ActiveMQ节点,用于存储“持久化”的“可用磁盘空间”。该子标记的limit属性必须要进行设置<storeUsage limit="100 gb"/></storeUsage><tempUsage>//一旦ActiveMQ做事节点存储的达到了memoryUsage的限定,非持久化就会被转储到 temp store区域,虽然我们说过非持久化不进行持久化存储,但是ActiveMQ为了防止“数据洪峰”涌现时非持久化大量堆积致使内存耗尽的情形涌现,还是会将非持久化写入到磁盘的临时区域——temp store。这个子标记便是为了设置这个tempstore区域的“可用磁盘空间限定”<tempUsage limit="50 gb"/></tempUsage></systemUsage></systemUsage>
从上面的配置我们须要get到一个结论,当非持久化堆积到一定程度的时候,也便是内存超过指定的设置阀值时,ActiveMQ会将内存中的非持久化写入到临时文件,以便腾出内存。但是它和持久化的差异是,重启之后,持久化会从文件中规复,非持久化的临时文件会直接删除
的持久化策略剖析
持久性对付可靠通报来说是一种比较好的方法,即时发送者和接管者不是同时在线或者中央在发送者发送后宕机了,在中央重启后仍旧可以将发送出去。持久性的事理很大略,便是在发送出去后,中央首先将存储在本地文件、内存或者远程数据库,然后把发送给接管者,发送成功后再把从存储中删除,失落败则连续考试测验。接下来我们来理解一下在broker上的持久化存储实现办法
持久化存储支持类型
ActiveMQ支持多种不同的持久化办法,紧张有以下几种,不过,无论利用哪种持久化办法,的存储逻辑都是同等的。Ø KahaDB存储(默认存储办法)
Ø JDBC存储
Ø Memory存储
Ø LevelDB存储
Ø JDBC With ActiveMQ Journal
KahaDB存储KahaDB是目前默认的存储办法,可用于任何场景,提高了性能和规复能力。存储利用一个事务日志和仅仅用一个索引文件来存储它所有的地址。KahaDB是一个专门针对持久化的办理方案,它对范例的利用模式进行了优化。在Kaha中,数据被追加到data logs中。当不再须要log文件中的数据的时候,log文件会被丢弃。
配置办法
<persistenceAdapter><kahaDB directory="${activemq.data}/kahadb"/></persistenceAdapter>
KahaDB的存储事理在data/kahadb这个目录下,会天生四个文件Ø db.data 它是的索引文件,实质上是B-Tree(B树),利用B-Tree作为索引指向db-.log里面存储的Ø db.redo 用来进行规复Ø db-.log 存储内容。新的数据以APPEND的办法追加到日志文件末端。属于顺序写入,因此存储是比较快的。默认是32M,达到阀值会自动递增Ø lock文件 锁,表示当前得到kahadb读写权限的broker
JDBC存储利用JDBC持久化办法,数据库会创建3个表:activemq_msgs,activemq_acks和activemq_lock。ACTIVEMQ_MSGS 表,queue和topic都存在这个表中ACTIVEMQ_ACKS 存储持久订阅的信息和末了一个持久订阅吸收的IDACTIVEMQ_LOCKS 锁表,用来确保某一时候,只能有一个ActiveMQ broker实例来访问数据库JDBC存储配置
<persistenceAdapter><jdbcPersistenceAdapter dataSource="# MySQL-DS " createTablesOnStartup="true" /></persistenceAdapter>
dataSource指定持久化数据库的bean,createT ablesOnStartup是否在启动的时候创建数据表,默认值是true,这样每次启动都会去创建数据表了,一样平常是第一次启动的时候设置为true,之后改成falseMysql持久化Bean配置
<bean id="Mysql-DS" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close"><property name="driverClassName" value="com.mysql.jdbc.Driver"/><property name="url" value="jdbc:mysql://192.168.11.156:3306/activemq?relaxAutoCommit=true"/><property name="username" value="root"/><property name="password" value="root"/></bean>
LevelDB存储
LevelDB持久化性能高于KahaDB,虽然目前默认的持久化办法仍旧是KahaDB。并且,在ActiveMQ 5.9版本供应了基于LevelDB和Zookeeper的数据复制办法,用于Master-slave办法的首选数据复制方案。不过,据ActiveMQ官网对LevelDB的表述:LevelDB官方建议利用以及不再支持,推举利用的是KahaDB
<persistenceAdapter><levelDBdirectory="activemq-data"/></persistenceAdapter>
Memory 存储基于内存的存储,内存存储紧张是存储所有的持久化的在内存中。persistent=”false”,表示不设置持久化存储,直接存储到内存中
<beans><broker brokerName="test-broker" persistent="false"xmlns="http://activemq.apache.org/schema/core"><transportConnectors><transportConnector uri="tcp://localhost:61635"/></transportConnectors> </broker></beans>
JDBC Message store with ActiveMQ Journal
这种办法战胜了JDBC Store的不敷,JDBC每次过来,都须要去写库和读库。ActiveMQ Journal,利用高速缓存写入技能,大大提高了性能。当消费者的消费速率能够及时跟上生产者的生产速率时,journal文件能够大大减少须要写入到DB中的。举个例子,生产者生产了1000条,这1000条会保存到journal文件,如果消费者的消费速率很快的情形下,在journal文件还没有同步到DB之前,消费者已经消费了90%的以上的,那么这个时候只须要同步剩余的10%的到DB。如果消费者的消费速率很慢,这个时候journal文件可以使以批量办法写到DB。Ø 将原来的标签注释掉Ø 添加如下标签
<persistenceFactory><journalPersistenceAdapterFactory dataSource="#Mysql-DS" dataDirectory="activemqdata"/></persistenceFactory>
Ø 在做事端循环发送。可以看到数据是延迟同步到数据库的
消费端消费的事理
我们知道有两种方法可以吸收,一种是利用同步壅塞的MessageConsumer#receive方法。另一种是利用监听器MessageListener。这里须要把稳的是,在同一个session下,这两者不能同时事情,也便是说不能针对不同采取不同的吸收办法。否则会抛出非常。至于为什么这么做,最大的缘故原由还是在事务性会话中,两莳花费模式的事务不好管控
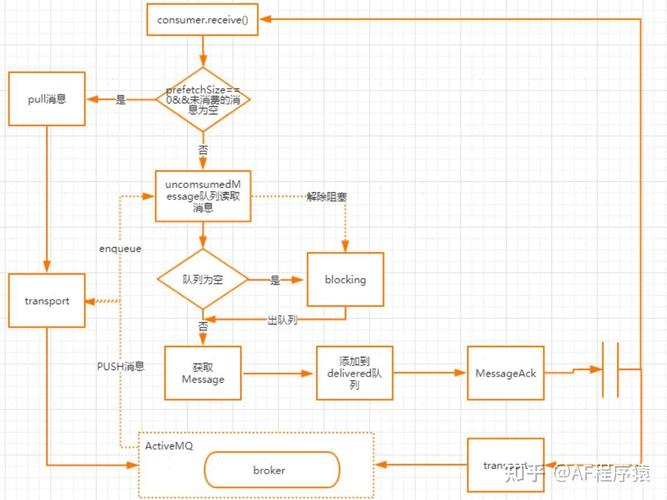
消费流程图
ActiveMQMessageConsumer.receive消费端同步吸收的源码入口
public Message receive() throws JMSException { checkClosed(); checkMessageListener(); //检讨receive和MessageListener是否同时配置在当前的会话中,同步消费不须要设置MessageListener 否则会报错 sendPullCommand(0); //如果PrefetchSizeSize为0并且unconsumerMessage为空,则发起pull命令 MessageDispatch md = dequeue(-1); //从unconsumerMessage出行列步队获取消息 if (md == null) { return null; } beforeMessageIsConsumed(md); afterMessageIsConsumed(md, false); //发送ack给到broker return createActiveMQMessage(md);//获取消息并返回}
sendPullCommand发送pull命令从broker上获取消息,条件是prefetchSize=0并且unconsumedMessages为空。unconsumedMessage表示未消费的,这里面预读取的大小为prefetchSize的值
protected void sendPullCommand(long timeout) throws JMSException { clearDeliveredList(); if (info.getCurrentPrefetchSize() == 0 && unconsumedMessages.isEmpty()) { MessagePull messagePull = new MessagePull(); messagePull.configure(info); messagePull.setTimeout(timeout); session.asyncSendPacket(messagePull); //向做事端异步发送messagePull指令 }}
clearDeliveredList
在上面的sendPullCommand方法中,会先调用clearDeliveredList方法,紧张用来清理已经分发的链表deliveredMessagesdeliveredMessages,存储分发给消费者但还未应答的链表Ø 如果session是事务的,则会遍历deliveredMessage中的放入到previouslyDeliveredMessage中来做重发Ø 如果session是非事务的,根据ACK的模式来选择不同的应答操作
// async (on next call) clear or track delivered as they may be flagged as duplicates if they arrive again private void clearDeliveredList() { if (clearDeliveredList) { synchronized (deliveredMessages) { if (clearDeliveredList) { if (!deliveredMessages.isEmpty()) { if (session.isTransacted()) { if (previouslyDeliveredMessages == null) { previouslyDeliveredMessages = new PreviouslyDeliveredMap<MessageId, Boolean>(session.getTransactionContext().getTransactionId()); } for (MessageDispatch delivered : deliveredMessages) { previouslyDeliveredMessages.put(delivered.getMessage().getMessageId(), false); } LOG.debug("{} tracking existing transacted {} delivered list ({}) on transport interrupt", getConsumerId(), previouslyDeliveredMessages.transactionId, deliveredMessages.size()); } else { if (session.isClientAcknowledge()) { LOG.debug("{} rolling back delivered list ({}) on transport interrupt", getConsumerId(), deliveredMessages.size()); // allow redelivery if (!this.info.isBrowser()) { for (MessageDispatch md: deliveredMessages) { this.session.connection.rollbackDuplicate(this, md.getMessage()); } } } LOG.debug("{} clearing delivered list ({}) on transport interrupt", getConsumerId(), deliveredMessages.size()); deliveredMessages.clear(); pendingAck = null; } } clearDeliveredList = false; } } } }
dequeue
从unconsumedMessage中取出一个,在创建一个消费者时,就会为这个消费者创建一个未消费的道,这个通道分为两种,一种是大略优先级行列步队分发通道SimplePriorityMessageDispatchChannel ;另一种是前辈先出的分发通道FifoMessageDispatchChannel.至于为什么要存在这样一个分发通道,大家可以想象一下,如果消费者每次去消费完一个往后再broker拿一个,效率是比较低的。以是通过这样的设计可以许可session能够一次性将多条分发给一个消费者。默认情形下对付queue来说,prefetchSize的值是1000
beforeMessageIsConsumed
这里面紧张是做消费之前的一些准备事情,如果ACK类型不是DUPS_OK_ACKNOWLEDGE或者行列步队模式(大略来说便是除了T opic和DupAck这两种情形),所有的先放到deliveredMessages链表的开头。并且如果当前是事务类型的会话,则判断transactedIndividualAck,如果为true,表示单条直接返回ack。 否则,调用ackLater,批量应答, client端在消费后暂且不发送ACK,而是把它缓存下来(pendingACK),等到这些的条数达到一定阀值时,只须要通过一个ACK指令把它们全部确认;这比对每条都逐个确认,在性能上要提高很多
private void beforeMessageIsConsumed(MessageDispatch md) throws JMSException { md.setDeliverySequenceId(session.getNextDeliveryId()); lastDeliveredSequenceId = md.getMessage().getMessageId().getBrokerSequenceId(); if (!isAutoAcknowledgeBatch()) { synchronized(deliveredMessages) { deliveredMessages.addFirst(md); } if (session.getTransacted()) { if (transactedIndividualAck) { immediateIndividualTransactedAck(md); } else { ackLater(md, MessageAck.DELIVERED_ACK_TYPE); } } } }
afterMessageIsConsumed
这个方法的紧张浸染是实行应答操作,这里面做以下几个操作Ø 如果过期,则返回过期的ackØ 如果是事务类型的会话,则不做任何处理Ø 如果是AUTOACK或者(DUPS_OK_ACK且是行列步队),并且是优化ack操作,则走批量确认ackØ 如果是DUPS_OK_ACK,则走ackLater逻辑Ø 如果是CLIENT_ACK,则实行ackLater
private void afterMessageIsConsumed(MessageDispatch md, boolean messageExpired) throws JMSException { if (unconsumedMessages.isClosed()) { return; } if (messageExpired) { acknowledge(md, MessageAck.EXPIRED_ACK_TYPE); stats.getExpiredMessageCount().increment(); } else { stats.onMessage(); if (session.getTransacted()) { // Do nothing. } else if (isAutoAcknowledgeEach()) { if (deliveryingAcknowledgements.compareAndSet(false, true)) { synchronized (deliveredMessages) { if (!deliveredMessages.isEmpty()) { if (optimizeAcknowledge) { ackCounter++; // AMQ-3956 evaluate both expired and normal msgs as // otherwise consumer may get stalled if (ackCounter + deliveredCounter >= (info.getPrefetchSize() .65) || (optimizeAcknowledgeTimeOut > 0 && System.currentTimeMillis() >= (optimizeAckTimestamp + optimizeAcknowledgeTimeOut))) { MessageAck ack = makeAckForAllDeliveredMessages(MessageAck.STANDARD_ACK_TYPE); if (ack != null) { deliveredMessages.clear(); ackCounter = 0; session.sendAck(ack); optimizeAckTimestamp = System.currentTimeMillis(); } // AMQ-3956 - as further optimization send // ack for expired msgs when there are any. // This resets the deliveredCounter to 0 so that // we won't sent standard acks with every msg just // because the deliveredCounter just below // 0.5 prefetch as used in ackLater() if (pendingAck != null && deliveredCounter > 0) { session.sendAck(pendingAck); pendingAck = null; deliveredCounter = 0; } } } else { MessageAck ack = makeAckForAllDeliveredMessages(MessageAck.STANDARD_ACK_TYPE); if (ack!=null) { deliveredMessages.clear(); session.sendAck(ack); } } } } deliveryingAcknowledgements.set(false); } } else if (isAutoAcknowledgeBatch()) { ackLater(md, MessageAck.STANDARD_ACK_TYPE); } else if (session.isClientAcknowledge()||session.isIndividualAcknowledge()) { boolean messageUnackedByConsumer = false; synchronized (deliveredMessages) { messageUnackedByConsumer = deliveredMessages.contains(md); } if (messageUnackedByConsumer) { ackLater(md, MessageAck.DELIVERED_ACK_TYPE); } } else { throw new IllegalStateException("Invalid session state."); } } }09 ActiveMQ的优缺陷
ActiveMQ 采取推送办法,以是最适宜的场景是默认都可在短韶光内被消费。数据量越大,查找和消费就越慢,积压程度与速率成反比。
缺陷
1.吞吐量低。由于 ActiveMQ 须要建立索引,导致吞吐量低落。这是无法战胜的缺陷,只要利用完备符合 JMS 规范的中间件,就要接管这个级别的TPS。2.无分片功能。这是一个功能缺失落,JMS 并没有规定中间件的集群、分片机制。而由于 ActiveMQ 是伟企业级开拓设计的中间件,初衷并不是为了处理海量和高并发要求。如果一台做事器不能承受更多,则须要横向拆分。ActiveMQ 官方不供应分片机制,须要自己实现。
适用场景
对 TPS 哀求比较低的系统,可以利用 ActiveMQ 来实现,一方面比较大略,能够快速上手开拓,另一方面可控性也比较好,还有比较好的监控机制和界面
不适用的场景
量巨大的场景。ActiveMQ 不支持自动分片机制,如果量巨大,导致一台做事器不能处理全部,就须要自己开拓分片功能。
原文链接:https://www.cnblogs.com/whgk/p/14155010.html















