
作者:玄弟 七锋
PolarDB-X 面向 HTAP 的稠浊实行器 一文详细解释了PolarDB-X实行器设计的初衷,其初衷一贯是致力于为PolarDB-X注入并行打算的能力,兼顾TP和AP场景,逐渐为其打造一款具备TB级数据处理能力的数据库。为了做到这一点,借鉴了各种数据库和大数据库产品,包括剖析型数据库,实时数仓等,吸取了各方面的上风来打造出一个全新的并行实行引擎。这里将对全体分布式并行实行框架做详细的先容,希望阅读之后对我们的实行器有一个全面的认识。

▶ 整体设计
PolarDB-X 是一个 Share Nothing 的数据库,采样了打算和存储分离的架构。个中数据以分片的形式存储于每个DN节点,打算节点叫CN。在打算过程中,DN和CN间、DN和DN、CN和CN间是通过千兆、万兆网络通信。每个CN节点上一样平常都会有调度组件、资源管理组件、RPC组件等。一个繁芜的查询,会被调度到多个CN节点上实行,考虑到数据一样平常都会根据均匀策略分到各个DN上,以是每个CN节点同时会访问多个DN。
当用户提交一条繁芜的SQL语句,每每须要访问多个DN节点,这个时候就会启动并行调度策略,全体实行步骤可以大略理解:
用户所连接的这个 CN 将承担查询折衷者(Query Coordinator)的角色;Query先发送给Query Coordinator,会首先经由优化器天生最新的Plan,然后会拆分到多个子操持(Fragment), 每个Fragment可能会包含多个实行算子。如果有的Framgnt卖力扫描DN的话,它里头必定包含Scan算子,从DN拉取数据;Fragment也可以包含Agg或者Join等其他算子;Query Coordinator里头的调度器(Task Scheduler)会按照定义的调度逻辑将各个Framgnts封装成Task,调度到得当的CN上实行,这里头可能会涉及到一些资源上的打算;各个CN收到Task后,会申请实行资源,布局实行的高下文,开始启动Task,并定期会向Query Coordinator申报请示状态;各个Task间会通过数据传输通道(DTL)交流数据,当所有的Task都实行完毕后,会将数据结果返回给Query Coordinator,由它卖力将结果返回给用户;成功返回给用户后,Query Coordinator和被调度到的各个CN节点的Task会做清理动作,开释打算资源。
全体流程大致就这样,有细心的同学会创造我们的框架在DN上有一层叫Split观点。我们的数据是按分片存储在各个DN上的,Split指的是数据分片partition的地址。对付包含扫描算子Scan的 Task,司帐算出须要访问哪些 partition,这些 partition 分布在哪些 DN 上,然后封装成splits按比例划分给这些扫描Task。但是实际运行过程中每个扫描Task并不是预分配好splits的,而是预分配部分splits给扫描Task,看哪一个Task扫描的更快就会从Query Coordinator连续获取余下splits,这样可以尽可能避免由于各个扫描Task资源不屈衡导致的消费长尾征象。但是如果一个表只被分成了2个分片,是不是意味着扫描任务至多只能是2,这可能起不到明显的并行加速效果。以是我们也支持在分片上连续按照分段做拆分,那么这个时候的Split除了会记录分片的地址,也会记录在分片上分段的位移。按照分段做拆分后,即便数据的分片数量有限,实行过程我们依然可以启动更多的扫描Task,并行去加速扫描。
▶ 实行操持
实行引擎实行的是由优化器天生的分布式实行操持。实行操持由算子组成。由于PolarDB-X的数据按照分片存储到各个的DN节点上去,实行操持实行也会尽可能的知够数据分布的locality,能下推的操持会被放到DN上实行,不能下推的操持会会被切分成一个个子操持(Fragment),会被放到各个CN节点上实行。以是这里我们须要关心如何将一个从优化器出来的操持,拆分成分布式操持,放到各个CN上实行?
为了更好地理解这个过程,我们这里以一条大略SQL: select from (select useid, count() as b from user_data group by userid) as T where T.b > 10 为例,经由优化器天生这样的相对最优操持:
针对并行实行操持,为了更高效地实行只管即便减少数据传输,可以把实行操持按照打算过程是否须要数据重分布(ReDistribution)分为不同片段(fragment)分布到相应节点实行,并且把一些操作下推来减少扫描输出的数据,上面的操持可能就变成这样的实行操持,由多个子片段构成。
不同片段之间通过 NetWork Write/Read 算子进行数据交流。更繁芜的比如多表关联(join)查询,会有更多的片段和更繁芜的数据交流模式。每个片段的并发度可以不同, 并发度是基于代价推导出来的。多机调度的基本单位是Stage,Stage记录了高下游片段的位置信息,以便高下游之间建立网络通道(DTL)。每个片段调度到打算CN节点后,会被封装成逻辑实行Task,比如fragment-1并发度是2的话,那么会将Task-1.0和Task-1.1 两个Task分别调度到两个CN节点。
Task仍旧是CN节点打算的逻辑单元,PolarDB-X实行器不仅仅可以支持单机并行能力(Parallel Query),也可以做多机并行(MPP)。以是在CN节点还引入了二层调度逻辑。当然二层调度的好处不仅仅于此,后面我们还会提到。这里会连续在Task内部根据算子间数据交流的特性,连续做切分,切分身分歧Pipeline。
不同的Pipeline并发度也可以不同,每个Pipeline会根据处理的数据规模大小司帐算出不同的并发度,天生详细的实行单元Driver,Driver间会根据二层调度确定高下游确当地通道(Local Channel)。
至此你该当可以理解从实行逻辑操持转化为分布式物理实行的全体过程。引入了一些新的名称,这里统一做下梳理:
Fragment:指的是逻辑实行操持按照打算过程中数据是否须要重分布,切割成的子操持。Stage:是由Fragment封装而成的调度逻辑单位,Stage除了封装Fragment外,还会记录高下游Stage间的调度位置信息。Task:Stage并不会在CN上直接运行,他们是通过并发度分解成一系列可调度到CN上的Task, Task依然是逻辑实行单元。Pipeline:对CN上的Task根据二层并发度做进一步切分,切分身分歧的Pipeline。Driver:一个Pipeline包含多个Driver,Driver是详细的实行单元,是一系列可运行算子的凑集。
一样平常来说针对一个繁芜查询,一个query包含多个Fragment,每个Fragment和Stage逐一对应,每个Stage包含多个Tasks,每个Task会切分身分歧的Pipeline,一个Pipeline包含了多个Driver。只有理解上面说的Fragment/Stage/Task/Pipeline/Driver这些观点,你才能更清楚理解我们接下来的设计。
▶ 调度策略
并行打算在运行之初,须要办理任务调度问题。调度的直白理解,便是将切分好的Task调度到各个CN节点去实行,充分利用各个CN的打算资源。这里头大家很随意马虎有这些疑问:
1. 实行过程中各个CN节点的打算资源是不屈衡了,那么在多机调度中是如何将各个Task打散到不同CN节点去实行? 2. 和各个DN交互的Task是如何并行的拉数据的?比如某个逻辑表分成了16个物理表,分布在4个DN节点上,有4个Driver去并行拉数据,每个Driver并不是均匀拉取4个物理表,而是根据自身的消费能力来确定拉取的物理表数量;多个Driver下发扫描任务会不会同时恰好落地一个DN节点上,导致某个DN成为瓶颈? 3. 我们完备可以在一个CN节点,同时调度多个Task实行,已经可以做到单机并行,为什么还要二层调度?
一层调度(多节点间)为理解决(1) 和 (2) 的问题,我们在CN节点内部引入了调度模块(Task Scheduler),紧张卖力Task在不同CN节点上的调度,这一层调度我们这里称之为一层调度,在这层调度中,同属于一个Stage的多个Task一定会被调度到不同CN节点上去,确保一个CN节点只能有相同tage的一个Task。调度过程中通过心跳不断掩护Task状态机,也掩护着集群各个CN节点Load信息,全体调度是基于CN Load做调度的。多机调度流程如下所示:
Resource Manager(RM)是CN节点上个一个资源管理模块,RM会借助Task心跳机制实时掩护集群各个CN节点的负载,Task Scheduler组件会基于负载选择得当的CN节点下发实行任务,比如CN-1 负载相对集群其他CN节点来说高很多,那么当前查询的Task会分发给其他CN节点,避免调度到CN-1节点去。实行器在实行Task任务时,Task并不是创建好的时候就确定了其消费DN splits的映射关系。各个Task按批次动态拉取splits进行消费, 直白理解便是谁的消费能力越强谁就有可能消费更多的splits。同样为理解决同一个时候多个任务同时消费同一个DN上的splits问题,我们在调度之初会将splits根据地址信息按照Zig-zag办法,把各个DN上的splits打散到全体splits queue上去,消费的时候可以尽可能分摊各个DN压力,这样打算过程中也会充分利用各个DN的资源。
有了一层调度后,我们也可以将同属于一个Stage的多个Task调度到同一个CN,这样实在也可以做到单机并行。如果这样设计的话,我们随意马虎忽略两个问题:
一层调度的逻辑比较繁芜,须要多次交互,一个CN内部须要同时掩护各个Task的状态,代价会比较大,这在TP场景是无法容忍的;一层调度中,并发度越高,天生Task就越多,这些Task间须要建立更多的网络传输通道。
二层调度(节点内部)为理解决上述一层调度的不敷,为此我们在参考Hyper的论文[1],引入了二层调度,既在CN节点内部单独做单机并行调度,大略来说我们会在Task内部借助CN确当地调度组件(Local Scheduler),对Task做进一步的并行调度,让Task在CN上实行,也可以做到并走运行。下图中,Stage-1和Stage-2是高下游关系,各自并发度都是9,调度到3个CN节点实行。如果只有一层并发度的话,每个CN节点还会调度运行3个Task,那么高下游之间统共会建立81个Channel,CN节点内部Task是相互独立的,这样缺陷还是很明显:
多个Channel,放大了网络开销,同一份buffer会被发送多次,发送和吸收对CPU和Memory都有代价;数据发送的工具是Task,数据本身有倾斜,会导致同节点内Task之间的负载不屈衡(hash skew),存在长尾问题。而一层调度和二层调度相结合的话,Stage-1和Stage-2的一层并发度是3,这样每个CN节点只会有1个Task,Task内部并发度3。由于shuffle的工具是Task,以是Stage-1和Stage-2间只会建立9个Channel,大大减少了网络开销,同时Task内部的3个Driver内数据是共享的,Task内部的所有的Driver可以共同消费接管到的数据,并行实行,避免长尾问题。针对付HashJoin,假设Ta为大表,Tb为小表,这两个表做HashJoin,可以让Ta和Tb同时shuffle到同一个节点做打算;也可以让小表Tb广播到Ta所在节点做打算,前者的网络代价是Ta+Tb,而后者的代价是NTb(N代表广播的份数)。以是如果只有一层调度的话,N可能比较大,实行过程中我们可能会选择两端做shuffle的实行操持;而一层和二层相结合的调度策略,可以让实行过程中选择BroadcastHashJoin,这样可以避免大表做shuffle,提高实行效率。
此外在二层调度策略中,task内部的多线程很随意马虎做到数据共享,有利于更高效的算法。如下图,同样是HashJoin过程中,build真个Task内部多个线程(driver)协同打算:build端收到shuffle的数据后,多线程协同建立一个共享的hash表。这样一个task只有一个build table,probe端收到shuffle数据后,也不用做ReDistribution了,直接读取接管到数据,进行并行的probe。
▶ 并行实行
聊完调度,接下来该当是关心任务是如何在CN上运行,运行过程中碰着非常我们系统是如何处理的呢?
线程模型
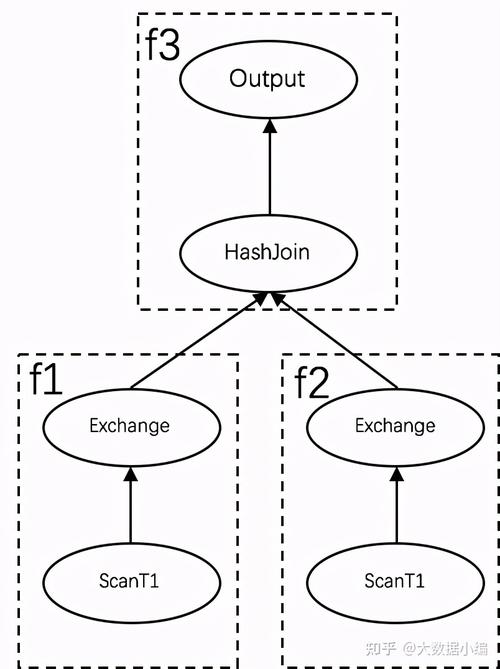
说到实行,有履历的同学可能会创造我们的调度并没有办理调度去世锁问题,比如对付下面这样一个实行操持,两表Join。一样平常会碰着两种问题:
1. 如果先调度f3和f2的话,这个时候假设集群没有调度资源,则f1不能迟迟调度起来。而HashJoin的逻辑便是须要先构建buildTable,这里f1刚好是build table部分。终极会导致实行去世锁:f1在等待f3和f2的打算资源开释,而f2和f3又在等待f1构建完buildTable;
2. 如果f1先调度起来了,假设这个时候f2和f3没有调度资源,这个时候f1从DN拉出来的数据,实在是无法发送给f3的,由于f3还没有被调度起来。
办理问题1,业界有很多办法,比较常见是在调度之初构建调度依赖关系(Scheduler Depedency):f1->f3-f2。而办理问题2,每每是将f1把DN拉出来的数据先放到内存中,实在放不下就落盘处理。可见处理上述两个问题,实行框架不仅仅须要在多机调度上做繁芜的调度依赖关系,同时还须要考虑对落盘的支持。而实在我们在调度的时候,并没有去考虑调度依赖这个事情,我们是一次性把f1/f2/f3全部调度起来了,这个是为何呢?这就要说下我们实行中的逻辑线程模型观点。在大多数打算引擎中,一个查询首先会通过资源调度节点,在各个CN上申请实行线程和内存,申请成功后,这些实行资源会被调度组件占用,用来分配当前查询的Task,不可以再被其他查询所利用,这种是真实的实行资源,和调度资源相互绑定,当CN上可利用的实行资源不足的时候,才会涌现调度去世锁问题。而在PolarDB-X中,我们并没有在调度的时候申请真实的线程资源,调度只须要考虑各个CN的负载,不须要考虑各个CN到底还剩多少可利用的真实资源。我们的线程模型也并没有和调度资源绑去世,每个Driver实在不独占一个真实的线程,换句话说,真实的线程也并没有和调度资源逐一对应。虽然说Driver是实行的基本单元,但是在调度上来看,它又是逻辑的线程模型而已。那是不是意味着只要有调度任务,都可以被成功调度到CN上去,答案是肯定的。一次性调度所有的实行单元到CN上去实行,对内存和CPU也是一种开销。比如f2被实行起来后,但是f1并没有实行完毕,那么f2也会不断实行,其数据实在也会被缓存起来,但是也不能无限缓存数据呀?为理解决这个问题,接下来就须要借助我们的韶光片实行了。
韶光片实行
我们在每个CN节点内部会有一组实行线程池来运行这些Driver,每个Driver会排队进入线程池参与打算,如果Driver被壅塞就会退出到Blocking行列步队中,等待被唤醒。比如f2 driver 启动后,从DN拉了数据放到有限空间buffer里头去,这个时候假设f1 driver都没有结束,那么f2 driver 对应的buffer就会满,满了后就会壅塞住,一旦壅塞我们的实行框架就会让f2 driver从实行器退出来,加入到Blocking行列步队中,大略的说便是将打算资源腾让出来,等待被唤醒。直到f1 driver都实行完毕后, f2 driver会被唤醒,实行框架就会将他移动到Pending行列步队中,等待被调度到实行线程池中连续运行。这里头还是会摧残浪费蹂躏点内存,但相对付CPU资源来说,内存资源还是比较充裕的。
韶光片实行的核心便是须要判断Driver何时会被Block的,总结起来被壅塞的缘故原由一样平常分为三种情形:
根据算子依赖模型来确定,比如图中f1 driver未实行完毕,那么f2 driver实在也会被壅塞(这个是一个可配置的选项);打算资源不敷(紧张指内存),对应的driver会被挂起,等待资源开释;等待DN相应,物理SQL下发给DN后,Driver会被挂起,等待物理SQL实行完毕。
除此之外我们在借鉴Linux 韶光片调度机制,会在软件层面上统计Driver的运行时长,超过阈值(500ms),也会被逼迫退出实行线程,加入到Pending行列步队,等待下一轮的实行调度。这种软件层面上的韶光片调度模型,可以办理繁芜查询永劫光占用打算资源问题。实在实现起来也挺大略的,便是每打算完一个批数据后,我们会对driver的运行时上进行统计,超过阈值,就退出线程池。下面贴出了Driver处理逻辑的部分伪代码,Driver在实行采取的是经典的Producer-Consumer模型,每消费一个Chunk我们就会累计韶光,当超过既定阈值,就会退出来。
任务状态机高并发系统,频繁地等待或者任务切换是常见的系统瓶颈。异步处理是一种已经被证明行之有效地避免这些瓶颈,把高并发系统性能推到极致的方法。以是PolarDB-X实行器的全体后端,统一利用全异步的实行框架;同时MPP实行过程涉及到多机的折衷,以是这就哀求我们在系统内部掩护这些异步状态。异步状态的掩护特殊主要,比如某个查询下的Task实行失落败,须要立即关照到全体集群中该查询正在运行的Task任务,以便立即中止,以防涌现Suspend Task,造成资源不开释问题。
以是在实行器内部,我们从三个维度(Task Stage Query)去掩护状态, 这三种State是相互依赖耦合的,比如Query 被Cancel,会立即关照其所有的Stage,各个Stage监听到状态变革,会及时关照给其所有的Task,只有等待Task都被Cancel后,Stage 末了的状态才变更为Cancel,终极Query的状态才被标记为Cancel。在这个过程中我们会引入对状态机异步监听机制,一旦状态发送变更就会异步回调干系处理逻辑。通过掩护这些状态,我们也可以及时通过查询或者监控诊断到任务是否非常,非常发生在哪个环节,也便于我们后期排查问题。
▶ 资源隔离如果并发要求过多的时候,资源紧张会让要求线程参与排队。但是正在运行的线程,须要耗费比较多的打算资源(CPU和Memory)的时候,会严重影响到其他正常正在运行的Driver。这对我们这种面向HTAP场景的实行器是决定不被许可的。以是在资源隔离这一块,我们会针对不同WorkLoad做打算资源隔离,但这种隔离是抢占式的。
CPU
在CPU层面上我们是基于CGroup做资源隔离的,根据WorkLoad不同我们把CPU资源分为AP Group和TP Group两组,个中对TP Group的CPU资源不限定;而对AP Group是基于CGroup做硬隔离,其CPU利用水位的最小阈值(cpu.min.cfs_quota)和最大阈值(cpu.max.cfs_quota)来做限定。实行线程分为三组: TP Core Pool 、AP Core Pool、SlowQuery AP Core Pool,个中后两者会被划分到AP Croup一组,做严格的CPU限定。Driver会根据WorkLoad划分到不同的Pool实行。看似很美的实现,这里头依然存在两个问题:
1. 基于COST识别的WorkLoad不准怎么办?
2. AP查询比较耗资源,在同一个Group下的多个慢查询相互影响怎么办?
涌现问题(1)紧张的场景是我们把AP类型的查询识别成了TP,结果会导致AP影响到TP,这是不可以接管的。以是我们在实行过程中会监视TP Driver的实行时长,超过一定阈值后仍没有结束的查询,会主动退出韶光片,然后将其它调度到AP Core Pool实行。而为理解决问题(2),我们会将AP Core Pool中永劫光运行都未结束的Driver,进一步做优雅降级,调度到SlowQuery AP Core Pool实行。个中SlowQuery AP Core Pool会设置实行权重,尽可能降落其实行Driver的频率。
MEMORY在内存层面上,会将CN节点堆内内存区域大致可以分为四大块:
TP Memory:用于存放TP打算过程中的临时数据AP Memory:用于存放AP打算过程中的临时数据Other:存放数据构造、临时工具和元数据等System Reserverd:系统保留内存
TP和AP Memory分别会有最大阈值和最小阈值限定,两者内存利用过程中可以相互抢占,但是基本原则是:TP Memory可以抢占AP Memory,直到查询结束才开释;而AP Memory可以抢占内存TP,但是一旦TP须要内存的时候,AP Memory须要立即开释内存,开释办法可以是自尽或者落盘。
▶ 数据传输层(DTL)并行打算是充分利用各个CN资源参与打算,那么DN与DN之间一定会存在数据交互。各个DN上的高下游的Task数据须要传输,比如上游的Task数量N,下贱的Task数量是M,那么他们之间的数据传输通道须要用到MN个通道(Channel),同样的我们将这些通道(Channel)的观点抽象成数据传输层。这个传输层的设计每每也会面临两个问题:
1. 通道分为发送端和接管端,当发送端源源不断发送数据,而接管端无法处理的话就会造成内存雪崩;
2. 数据在传输过程中丢失。
在业界实现数据传输紧张有两种传输办法:Push和Pull。Push便是发送端往接管端推送数据,这里头为了避免吸收端处理不过来,须要引入流控逻辑,一样平常的做法都是在吸收端预留了槽位,当槽位被数据占满时会关照发送端停息发送数据,当有吸收端数据被消费空闲槽位涌现时关照发送端连续发送,这里头会涉及到发送端和吸收真个多次交互,流控机制相比拟较繁芜。Pull便是发送端将数据先发送到buffer里头去,吸收端按需从发送真个的buffer拉数据,而当发送端发送的数据到buffer,吸收端假设永劫光不来拉数据,末了发送端buffer满了,也会触发上游反压,为了避免频繁反压,每每发送真个buffer不应该设置太小。综合起来我们选择了pull办法来做。采样pull办法也会碰着两个问题:
1. 每个receiver一样平常会和上游多个sender建立连接,那么每次都是通过广播的办法从上游所有的sender拉数据吗?
2. 一次从sender端到底要求多少的数据呢,即averageBytesPerRequest?
我们先回答问题(2),我们这里会记录上一次要求的数据量lastAverageBytesPerRequest、当前建连通道个数n以及上一次统共返回的数据量responseBytes,来打算出当前averageBytesPerRequest,详细的公式下面也给出了。至于问题(1),有了当前的averageBytesPerRequest后,结合目前receiver上buffer剩余空间,可以估算出这一次须要向上游几个sender发送要求。
在异步通信过程中为了担保传输可靠性,我们采取了类似tcp ack的办法,当receiver端带着token去上游拉数据的时候,则表示当前token之前的数据均已经被receiver端消费完毕,sender可以开释这些数据,然后将下一批数据以及nextToken返回给receiver端。
▶ 效果展示
前后说了很多干货,下面咱们来点大略实际的东西。这里以TPCH Q13为例来演示下实行器在不同场景下的加速效果,为了方便截图在Q13后面都加了limit。该测试环环境下,CN和DN规格都是216C64G。
单机单线程下运行,耗时3min31s
利用Parallel Query加速,既单机多线程实行,耗时23.3s
利用MPP加速,既同时利用两个CN节点的资源打算,耗时11.4s
▶ 总结不管是大略查询,还是 Parallel Query和MPP场景下的繁芜查询,共用的都是一套实行框架。不同场景下对实行器的哀求,更多的是并发度设置和调度策略的差异。相对付业界其他产品来说,PolarDB-X实行器紧张特点:
在资源模式上利用的是轻量化的资源管理,不像大数据打算引擎,须要额外引入的资源管理的节点,做严格的资源预分配,紧张考虑到我们的场景是针对付小集群的在线打算;在调度模型上实行器支持DAG调度,相对付MPP调度可以做到更加灵巧的并发掌握模型,各个Stage间、Pipeline间的并发可以不一样;差异与其他产品,AP加速引用的是外挂并行打算引擎,PolarDB-X并行实行器是内置的,不同查询间共用一套实行模型,确保TP和AP享有同等的SQL兼容性。
PolarDB-X并行打算在线上已经平稳运行了近两年,这两年来我们不仅仅在实行框架上做了很多稳定性事情,在算子层的优化我们也沉淀了不少的技能。但这些还不足,目前比较热的是自适应实行,结合Pipeline模式的自适应实行寻衅比较大,我们近期也在研究,欢迎感兴趣的朋友来拍拍砖,一起进步!
本文为阿里云原创内容,未经许可不得转载。















