
Dropout (Hinton et al.[2012]) 是提高深度神经网络(DNN)泛化能力的紧张正则化技能之一。由于其大略、高效的特点,传统 dropout 及其他类似技能广泛运用于当前的神经网络中。dropout 会在每轮演习中随机忽略(即 drop)50% 的神经元,以避免过拟合的发生。如此一来,神经元之间无法相互依赖,从而担保了神经网络的泛化能力。在推理过程中会用到所有的神经元,因此所有的信息都被保留;但输出值会乘 0.5,使均匀值与演习韶光同等。这种推理网络可以看作是演习过程中随机天生的多个子网络的凑集。Dropout 的成功推动了许多技能的发展,这些技能利用各种方法来选择要忽略的信息。例如,DropConnect (Wan et al. [2013]) 随机忽略神经元之间的部分连接,而不是神经元。
本文阐述的也是一种 dropout 技能的变形——multi-sample dropout。传统 dropout 在每轮演习时会从输入中随机选择一组样本(称之为 dropout 样本),而 multi-sample dropout 会创建多个 dropout 样本,然后均匀所有样本的丢失,从而得到终极的丢失。这种方法只要在 dropout 层后复制部分演习网络,并在这些复制的全连接层之间共享权重就可以了,无需新运算符。

通过综合 M 个 dropout 样本的丢失来更新网络参数,使得终极丢失比任何一个 dropout 样本的丢失都低。这样做的效果类似于对一个 minibatch 中的每个输入重复演习 M 次。因此,它大大减少了演习迭代次数。
实验结果表明,在基于 ImageNet、CIFAR-10、CIFAR-100 和 SVHN 数据集的图像分类任务中,利用 multi-sample dropout 可以大大减少演习迭代次数,从而大幅加快演习速率。由于大部分运算发生在 dropout 层之前的卷积层中,Multi-sample dropout 并不会重复这些打算,以是对每次迭代的打算本钱影响不大。实验表明,multi-sample dropout 还可以降落演习集和验证集的缺点率和丢失。
Multi-Sample Dropout
图 1 是一个大略的 multi-sample dropout 实例,这个实例利用了 2 个 dropout 样本。该实例中只利用了现有的深度学习框架和常见的操作符。如图所示,每个 dropout 样本都复制了原网络中 dropout 层和 dropout 后的几层,图中实例复制了「dropout」、「fully connected」和「softmax + loss func」层。在 dropout 层中,每个 dropout 样本利用不同的掩码来使其神经元子集不同,但复制的全连接层之间会共享参数(即连接权重),然后利用相同的丢失函数,如交叉熵,打算每个 dropout 样本的丢失,并对所有 dropout 样本的丢失值进行均匀,就可以得到终极的丢失值。该方法以末了的丢失值作为优化演习的目标函数,以末了一个全连接层输出中的最大值的类标签作为预测标签。当 dropout 运用于网络尾段时,由于重复操作而增加的演习韶光并不多。值得把稳的是,multi-sample dropout 中 dropout 样本的数量可以是任意的,而图 1 中展示了有两个 dropout 样本的实例。
图 1:传统 dropout(左)与 multi-sample dropout(右)
神经元在推理过程中是不会被忽略的。只打算一个 dropout 样本的丢失是由于 dropout 样本在推理时是一样的,这样做可以对网络进行修剪以肃清冗余打算。要把稳的是,在推理时利用所有的 dropout 样本并不会严重影响预测性能,只是轻微增加了推理韶光的打算本钱。
为什么 Multi-Sample Dropout 可以加速演习
直不雅观来说,带有 M 个 dropout 样本的 multi-sample dropout 的效果类似于通过复制 minibatch 中每个样本 M 次来将这个 minibatch 扩大 M 倍。例如,如果一个 minibatch 由两个数据样本(A, B)组成,利用有 2 个 dropout 样本的 multi-sample dropout 就犹如利用传统 dropout 加一个由(A, A, B, B)组成的 minibatch 一样。个中 dropout 对 minibatch 中的每个样本运用不同的掩码。通过复制样本来增大 minibatch 使得打算韶光增加了近 M 倍,这也使得这种办法并没有多少实际意义。比较之下,multi-sample dropout 只重复了 dropout 后的操作,以是在不显著增加打算本钱的情形下也可以得到相似的收益。由于激活函数的非线性,传统方法(增大版 minibatch 与传统 dropout 的组合)和 multi-sample dropout 可能不会给出完备相同的结果。然而,如实验结果所示,迭代次数的减少还是显示出了 multi-sample dropout 的加速效果。
实验
Multi-Sample Dropout 带来的改进
图 2 展示了三种情形下(传统 dropout、multi-sample dropout 和不该用 dropout 进行演习)的演习丢失和验证集偏差随演习韶光的变革趋势。本例中 multi-sample dropout 利用了 8 个 dropout 样本。从图中可以看出,对付所有数据集来说,multi-sample dropout 比传统 dropout 更快。
图 2:传统 dropout 和 multi-sample dropout 的演习集丢失和验证集偏差随演习韶光的变革趋势。multi-sample dropout 展现了更快的演习速率和更低的缺点率。
表 1 总结了终极的演习集丢失、演习集缺点率和验证集缺点率。
表 1:传统 dropout 和 multi-sample dropout 的演习集丢失、演习集缺点率和验证集缺点率。multi-sample dropou 与传统 dropout 比较有更低的丢失和缺点率。
参数对性能的影响
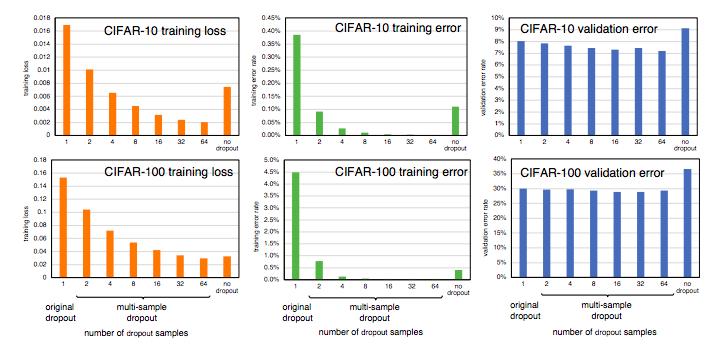
图 3 (a) 和图 3 (b) 比较了不同数量 dropout 样本和不同的 epoch 下在 CIFAR-100 上的演习集丢失和验证集偏差。利用更多的 dropout 样本加快了演习的进度。当 dropout 样本多达 64 个时,dropout 样本的数量与演习丢失的加速之间显现出明显的关系。对付图 3(b) 所示的验证集偏差,dropout 样本在大于 8 个时,再增加 dropout 样本数量不再能带来显著的收益。
图 3:不同数量的 dropout 样本在演习过程中的演习集丢失和验证集偏差。
表 2:不同 dropout 样本数量下与传统 dropout 的迭代韶光比较。增加 dropout 样本的数量会增加迭代韶光。由于内存不敷,无法实行有 16 个 dropout 示例的 VGG16。
图 4:不同数量的 dropout 样本演习后的丢失和缺点率。
图 5:(a) 验证缺点率,(b) 不同 dropout 率下的 multi-sample dropout 和传统 dropout 的演习丢失趋势。个中 35% 的 dropout 率表示两个 dropout 层分别利用 40% 和 30%。
图 6:有水平翻转(增加 dropout 样本多样性)和没有水平翻转时演习丢失的比较。x 轴表示 epoch 数。
为什么 multi-sample dropout 很高效
如前所述,dropout 样本数为 M 的 multi-sample dropout 性能类似于通过复制 minibatch 中的每个样本 M 次来将 minibatch 的大小扩大 M 倍。这也是 multi-sample dropout 可以加速演习的紧张缘故原由。图 7 可以解释这一点。
图 7:传统 dropout 加数据复制后的 minibatch 与 multi-sample dropout 的比较。x 轴表示 epoch 数。为了公正的比较,研究者在 multi-sample dropout 中没有利用会增加样本多样性的横向翻转和零添补。
论文链接:https://arxiv.org/pdf/1905.09788.pdf















