
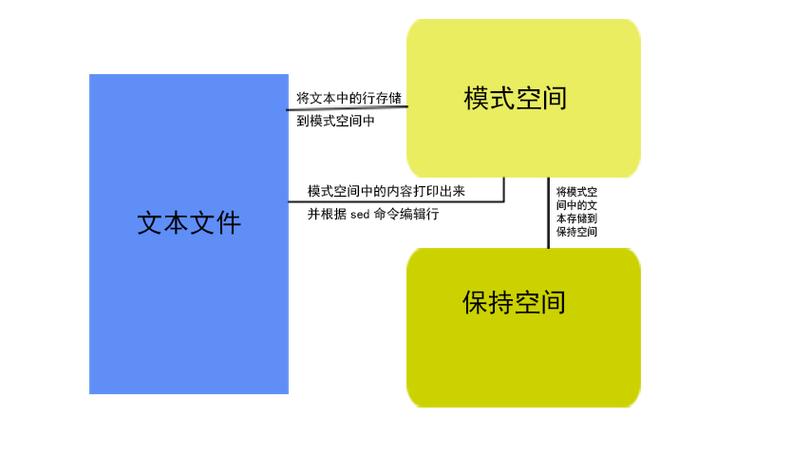
流程:Sed软件从文件或管道中读取一行,处理一行,输出一行;再读取一行,再处理一行,再输出一行……
模式空间:sed软件内部的一个临时缓存,用于存放读取到的内容。

2、命令格式:sed [选项] [命令] [输入文件]
sed命令的常用选项:
-n :只打印模式匹配的行,一样平常与 p 一起利用。如:sed -n ' 2p ' /data 表示输出/data的第二行,如:sed -n '20,30p' /data/boy显示 /data/boy的20到30行。
-e :进行多项编辑,即对输入行运用多条sed命令时利用,此为默认选项。如:sed -e '/^#/d' -e '/^$/d' /data/boy表示删除空格的行和#开头的行。
-f :将sed的动作写在一个脚本文件内,用–f filename 实行filename内的sed动作。
-r :支持扩展表达式
-i :直接修正文件内容,如:sed -i s#old#new#g
常用基本命令:
d :delete, 删除匹配到的行;
p :print, 显示匹配到的行;常日 p 会与参数 sed -n 一起用
a \text:append, 在指定行后追加文本text,支持利用\n实现多行追加;
i \text :insert, 在指定行前插入文本text,支持利用\n实现多行插入;
c \text:将指定行的内容更换为文本text;
w /file:write, 保存模式空间中匹配到的行至指定的文件中;
r /file :read, 将指定文件的内容读取至当前模式空间中被匹配到的行后面,常用于实现文件合并;
sed -i '/Ethernet/r myfile' test 匹配Ethernet的行,读进来另一个文件的内容,读进来的文件的内容会插入到匹配Ethernet的行后
s/pattern/replaces/:查找pattern用replaces更换;分隔符可自行指定,常用的分隔符有/, #, @等;
更换标记:
g:全局更换;
w /file:将更换的结果保存至指定文件中;sed -i 's/pattern/replaces/w my.txt' test 将更换后的结果保存到my.txt中
p:显示更换成功的行;
y:用于(对应)转换字符;
=:打印行号;
! :匹配后取反;
l :打印行号,并显示掌握字符;
q:读取匹配到的行退却撤退出;
3、sed在文件中查询文本的办法
x/p
查询第x行
sed -n '2p ' /datax,y/p查询从x到y行sed -n '1,3p ' /data/pattern/p查询包含pattern的行sed -n '/pattern/p' /data/pattern 1/,/pattern 2/p查询包含pattern 1或pattern 2的行sed -n '/pn1/,/pn2/p' /data/pattern/,xp查询从包含pattern的行到x行
sed -n '/pn/,5p' /datax,/pattern/p查询从x到包含pattern的行sed -n '5,/pn/p' /datax,y!p查询不包含指定行号x和y的行sed -n '5,8!p' /data
10{sed-commands} 对第10行操作 10,20{sed-commands} 对10到20行操作,包括第10,20行 10,+20{sed-commands} 对10到30(10+20)行操作,包括第10,30行 1~2{sed-commands} 对1,3,5,7,……行操作 10,${sed-commands} 对10到末了一行($代表末了一行)操作,包括第10行 /oldboy/{sed-commands} 对匹配oldboy的行操作 /oldboy/,/Alex/{sed-commands} 对匹配oldboy的行到匹配Alex的行操作 /oldboy/,${sed-commands} 对匹配oldboy的行到末了一行操作 /oldboy/,10{sed-commands} 对匹配oldboy的行到第10行操作,把稳:如果前10行没有匹配到oldboy,sed软件会显示10行往后的匹配oldboy的行,如果有。 1,/Alex/{sed-commands} 对第1行到匹配Alex的行操作 /oldboy/,+2{sed-commands} 对匹配oldboy的行到其后的2行操作4、案例(sed 后不跟 -i 表示仅对输出改变,对源文件不改变)
单行增加到第2行后: sed '2a 106,dandan,CSO' person.txt单行增加到第2行前: sed '2i 106,dandan,CSO' person.txt多行增加到第2行前: sed '2i 106,dandan,CSO\n107,bingbing,CCO' person.txt,每行之间加换行符 \n删除第二行: sed '2d' person.txt删除匹配oldboy或者Alex的行 sed '/oldboy/,/Alex/d' person.txt用新行替代第2行 sed '2c 106,dandan,CSO' person.txt分组更换\( \)和\1的利用解释sed软件的\( \)的功能可以记住正则表达式的一部分,个中,\1为第一个记住的模式即第一个小括号中的匹配内容,\2第二记住的模式,即第二个小括号中的匹配内容,sed最多可以记住9个。
例:echo I am oldboy teacher.如果想保留这一行的单词oldboy,删除剩下的部分,利用圆括号标记想保留的部分。
echo I am oldboy teacher. |sed 's#^.am \([a-z].\) tea.$#\1#g'
思路:用oldboy字符更换I am oldboy teacher.
下面阐明用□代替空格:
^.am□ –>这句的意思因此任意字符开头到am□为止,匹配文件中的I am□字符串;
\([a-z].\)□–>这句的外壳便是括号\(\),里面的[a-z]表示匹配26个字母的任何一个,[a-z].合起来便是匹配任意多个字符,本题来说便是匹配oldboy字符串,由于oldboy字符串是须要保留的,因此用括号括起来匹配,后面通过\1来取oldboy字符串。
□tea.$–>表示以空格tea起始,任意字符结尾,实际便是匹配oldboy字符串后,紧接着的字符串□teacher.;
后面被更换的内容中的\1便是取前面的括号里的内容了,也便是我们要的oldboy字符串。
()是扩展正则表达式的元字符,sed软件默认识别基本正则表达式,想要利用扩展正则须要利用\转义,即\(\)。sed利用-r选项则可以识别扩展正则表达式,此时利用\(\)反而会出错。
转载地址:https://blog.51cto.com/12674559/2096253
博客作者九五杠一的原创作品















