
在利用ForeSpider采集数据时,我们有时会碰着利用定位过滤、地址过滤、定位取值等采集不出来的情形。这种情形一样平常是由于数据在其他的要求中导致的。
网站要求一样平常分为两种,分别是GET要乞降POST要求,本教程将分别先容两种要求的配置采集方法。在开始配置之前须要先节制,如何精准找到数据所在的要求,并判断要求类型。

我们以东方财富网页面中图表数据为例进行演示。
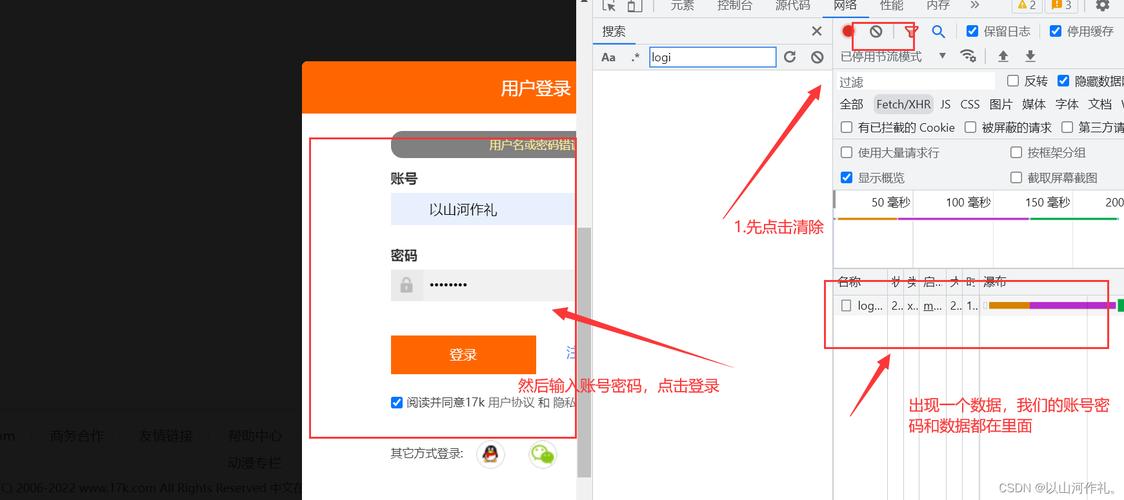
1. 打开须要采集页面,点击F12,打开Network界面,然后刷新网页,创造多了很多要求。
2. 须要采集表格中的数据,复制任意一个数据值,在搜索框进行搜索,就会把数据所在的要求筛选出来。
3. 双击链接即可找到对应要求返回的内容,可查看是否包含所有表格中的数据。
4.打开该要求的要求头,不雅观察是哪种要求,如下图所示,表示该数据在get要求中。
以下为post要求示例:
GET要乞降POST要求最直不雅观的差异便是:
GET把参数包含在URL中,POST通过request body通报参数。
l 采集GET要求中的数据
【事理】
找到GET要求链接规律,然后用脚本拼写要求链接,打开要求获取要求中所须要的链接/数据。
【脚本讲解】
采集微博热搜某热搜数据页
1. 查找数据所在要求
2. 拼要求并打开要求
var link=URL.urlname.ReplaceAll("#","%23");//拼写为要求网址var doc = EXTRACT.OpenDoc(CHANN,link,"",);//打开要求if(doc){}EXTRACT.CloseDoc(doc);//关闭要求,固定搭配
3. 不雅观察要求内数据位置并用脚本提取出所须要的数据
根据数据构造,用脚本抽取数据并返回,数据抽取全部脚本如下所示:
var link=URL.urlname.ReplaceAll("#","%23");var doc = EXTRACT.OpenDoc(CHANN,link,"",);if(doc){ var a=doc.GetDom(); var b = a.FindClass("m-note"); var c=b.next.child; while(c){ var d=a.FindClass("card",div,c); record re; re.id = c.mid; re.pubname= a.GetTextAll(d.child.child.next.child.child.next.child); re.pubtime = a.GetTextAll(d.child.child.next.child.next.child); re.text = a.GetTextAll(d.child.child.next.child.next.next); re.transmit=a.GetTextAll(d.child.next.child.child.child); re.comment_=a.GetTextAll(d.child.next.child.child.next.child); re.click=a.GetTextAll(d.child.next.child.child.next.next.child.child); RESULT.AddRec(re,this.schemaid); c=c.next; } }EXTRACT.CloseDoc(doc);
微博热搜完全教程:
【从零开始学爬虫】采集微博热搜数据
完全视频教程:
采集微博热搜数据视频教程
l 采集POST要求中的数据
【事理】
找到POST要求链接规律,然后用脚本拼写要求链接及request body通报参数,打开要求获取要求中所须要的链接/数据。
【脚本讲解】
采集百度翻译数据页
1.找到数据所在要求
不雅观察数据要求链接手法同上,找到要求查看header,创造该要求为post要求。
在request head中找到Cookie、refer,在request body中找到FormData,如下图所示:
不雅观察创造,不同的翻译要求链接,cookie和refer不变,FormData中的query内容变革,而且query参数即为须要翻译的英文文本。
2.用脚本拼出这个post要求并打开要求
脚本文本:
var table = DATADB.Open("news"); //打开数据表newsvar recs = table.Query(""); //查询条件为空for(k in recs each v)//调用每个数据{ record re;//定义一个返回值,返回数据固定搭配 var transid = v.id;//调用news中的id var trans = v.content;//调用news中的content var con=trans;//待翻译的笔墨 var link="https://fanyi.baidu.com/transapi";//link为要求链接 var header;//定义一个要求头 var header; header.cookie = "";////定义要求头的cookie,与网页上的cookie同等 header.refer = "";//定义要求头的refer,与网页上的refer同等 var post="from=en&to=zh&query="+con+"&source=txt";//定义post,将FormData拼出来 var doc = EXTRACT.OpenDoc(CHANN,link,post,header);//打开post要求 if(doc){ EXTRACT.CloseDoc(doc);//关闭要求,固定搭配 }}
3.不雅观察数据所在位置,并用脚本提取数据
打开这个要求的preview预览界面,不雅观察翻译后的数据位置,
根据数据所在位置,编写脚本提取数据并返回。
脚本文本:
var table = DATADB.Open("news"); //打开数据表newsvar recs = table.Query(""); //查询条件为空for(k in recs each v)//调用每个数据{ record re;//定义一个返回值,返回数据固定搭配 var transid = v.id;//调用news中的id var trans = v.content;//调用news中的content var con=trans;//待翻译的笔墨 var link="https://fanyi.baidu.com/transapi";//link为要求链接 var header;//定义一个要求头 header.cookie = "";////定义要求头的cookie,与网页上的cookie同等 header.refer = "";//定义要求头的refer,与网页上的refer同等 var post="from=en&to=zh&query="+con+"&source=txt";//定义post,将FormData拼出来 var doc = EXTRACT.OpenDoc(CHANN,link,post,header);//打开post要求 if(doc){ var str = doc.GetDom().GetSource().ToStr();//打开要求后,将获取要求源码并转为字符串格式 JScript js;//定义一个js var obj = js.RunJson(str);//跑一下js var a="";//定义一个变量a for(i=0;i<obj.data.length;i++){ var search=obj.data[i].dst;//取obj中的data中的第i个工具的dst值 var ttt=search.ReplaceAll("u","\\u");//将search文本中的u用\\u更换 ttt=ttt.ToStr();//转为字符串 var trans_con=doc.GetDom().UnEscape(ttt);//unicode转中文 a+=trans_con;//a为a+trans_con } re.id=transid;//返回id re.trans_con=a;//返回翻译后内容 RESULT.AddRec(re,this.schemaid);//返回一个数据 EXTRACT.CloseDoc(doc);//关闭要求,固定搭配 }
百度翻译完全教程:
【从零学爬虫】一文学会批量翻译
l知识点总结
1.OpenDoc
【方法】OpenDoc(item,addr_or_keyForm,postData="",header=0)
【解释】用当前采集节点打开一个文档(必须与CloseDoc成对利用)
【参数解释】
item:一个采集器的频道节点[channel],频道脚本用this,其它地方用CHANN
addr_or_keyForm:打开地址或者class="vartypestd">keyForm工具
postData:post数据(如果为Post)[keyForm工具时,postData参数忽略]
header:写入http协议头数据[该参数为一个工具{refer:"指定refer地址",cookie:"cookie数据"},工具全部可用成员见下方]
2.CloseDoc
【方法】CloseDoc(doc)
【解释】关闭打开的采集文档
【参数解释】doc表示打开的文档
3.OpenDoc方法的参数header工具的全部可用成员
本教程仅供传授教化利用,严禁用于商业用场!
ForeSpider免费版本下载地址
l 前嗅简介
前嗅大数据,海内领先的研发型大数据专家,多年来致力于为大数据技能的研究与开拓,自主研发了一整套从数据采集、剖析、处理、管理到运用、营销的大数据产品。前嗅致力于打造海内第一家深度大数据平台!















