
先摆出结论吧。结论包含两点,即write调用不能担保什么以及write调用能担保什么。
首先,write调用不能担保你哀求的调用是原子的,以下面的调用为例:

ret = write(fd, buff, 512);
Linux无法担保将512字节的buff写入文件这件事是原子的,由于:
如果不考虑以上这些成分,write调用为什么不设计成直接返回True或者False呢?要么成功写入512字节,要么一点都不写入,这样岂不更好?之以是不这么设计,正是基于上述不可回避的成分来考虑的。
在系统调用设计的意义上,不信赖的代价大于信赖,最坏的考虑优先于乐不雅观地盲进。
其次,write调用能担保的是,不管它实际写入了多少数据,比如写入了n字节数据,在写入这n字节数据的时候,在所有共享文件描述符的线程或者进程之间,每一个write调用是原子的,不可打断的。举一个例子,比如线程1写入了3个字符’a’,线程2写入了3个字符’b’,结果一定是‘aaabbb’或者是‘bbbaaa’,不可能是类似‘abaabb’这类交错的情形。
大概你自然而然会问一个问题,如果两个进程没有共享文件描述符呢?比如进程A和进程B分别独立地打开了一个文件,进程A写入3个字符’a’,进程B写入了3个字符’b’,结果若何呢?
答案是,这种情形下没有任何担保,终极的结果可能是‘aaabbb’或者是‘bbbaaa’,也可能是‘abaabb’这种交错的情形。如果你希望不交错,那么怎么办呢?答案也是有的,那便是在所有写进程打开文件的时候,采取O_APPEND办法打开即可。
作为一个和用户态交互的范例系统调用,write无法担保用户哀求的事情是原子的,但它在共享文件的范围内能担保它实际完成的事情是原子的,在非共享文件的情形下,虽然它乃至无法担保它完成的事情是原子的,但是却供应了一种机制可以做到这种担保。可见,write系统调用设计的非常之好,边界十分清晰!
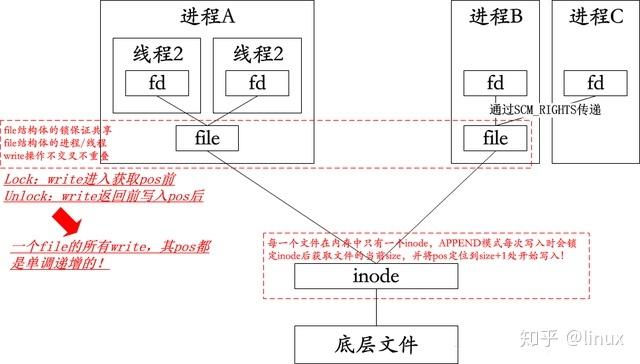
关于以上的这些担保是如何做到的,下面简要地阐明下。我本来是不想阐明的,但是看了下面的阐明后,对付理解上述的担保很有帮助,以是就不得不追加了。阐明归于下图所示:
总结一下套路:
APPEND模式通过锁inode,担保每次写操作均在inode中获取的文件size后追加数据,写完后开释锁;非APPEND模式通过锁file构造体后获取file构造体的pos字段,并将数据追加到pos后,写完更新pos字段后开释锁。由此可见,APPEND模式供应了文件层面的全局写安全,而非APPEND模式则供应了针对共享file构造体的进程/线程之间的写安全。
值得几次再三重申的是,由于write调用只是在inode或者file层面上担保一次写操作的原子性,但无法担保用户须要写入的数据的一次肯定被写完,以是在多线程多进程文件共享情形下就须要用户态程序自己来应对short write问题,比如设计一个锁保护一个循环,直到写完成或者写出错,不然循环不退出,锁不开释…
此外,我们知道,apache,nginx以及其余一些做事器写日志都是通过APPEND来担保独立原子写入的,要知道这些日志对付这类做事器而言是极度主要的。
本文写到这里貌似该当可以结束了,但是下面才是重头戏!
须要C/C++ Linux做事器架构师学习资料后台私信“资料”(资料包括C/C++,Linux,golang技能,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享
我写了一个剖析TCP数据包的程序,通过不断打日志的办法把数据包的信息记录在文件里,程序是个多线程程序,大概10多个线程同时写一个内存文件系统的文件,末了我创造少了一条日志!
程序本身不是重点,我可以通过以下的小程序代之阐明:
#include <stdio.h>#include <stdlib.h>#include <sys/types.h>#include <sys/stat.h>#include <fcntl.h>#include <sys/prctl.h>#include <string.h>#include <unistd.h>char a[512];char b[16];int main(){ int fd; memset(a, 'a', 512); memset(b, '-', 16); fd = open("/usr/src/probe/test.txt", O_RDWR|O_CREAT|O_TRUNC, 0660); if (fork() == 0) { prctl(PR_SET_NAME, (unsigned long)"child"); write(fd, b, 16); exit(0); } write(fd, a, 512); exit(0);}
编译为parent并运行,你猜猜末了test.txt里面是什么内容?
由于父子进程是共享fd指示的file构造体的,按照上面的阐明,终极的文件内容肯定是下面两种中的一种:
----------------aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa1
或者:
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa----------------1
可是,事实并不是这样!
事实上,在很小的概率下,文件中只有512个字符‘a’,没有看到任何字符‘-‘(当然还会有别的情形)!
Why?
你能理解,当事实和理论剖析不符的时候是多么痛楚,标准上明明便是说要担保共享file构造体的进程/线程一次写操作的原子性,然而事实证明有部分内容确实是被覆盖了,这显然并不合理。
再者说了,系统调用在设计之初就要做出某种级别的担保,比如一次操作的原子性等等,这样的系统API才更友好,我相信标准是对的,以是我就以为这是代码的BUG所致。是这么个思路吗?
不!
上面的这段话是事后诸葛亮的言辞,本文实在是一篇倒叙,是我先创造了写操作被覆盖,进而去逐步排查,终极才找到本文最开始的那段理论的,而不是反过来。以是,在我看到这个莫名其妙的缺点后,我并不知道这是否合理,我只是依赖崇奉以为这次又是内核的BUG!
然而我如何来证明呢?
首先我要想到一个写操作被覆盖的场景,然后试着去重现这个场景,终极去修复它。首先第一步还是看代码,出问题的内核是3.10社区版内核,于是我找到源码:
SYSCALL_DEFINE3(write, unsigned int, fd, const char __user , buf, size_t, count){ struct fd f = fdget(fd); ssize_t ret = -EBADF; if (f.file) { loff_t pos = file_pos_read(f.file); ret = vfs_write(f.file, buf, count, &pos); file_pos_write(f.file, pos); fdput(f); } return ret;}
说实话,这段代码我是剖析了足足10分钟才创造一个race的。大略讲,我把这个别系调用分解为了三部分:
get posvfs_writeupdate posrace发生在1和2或者2和3之间。以下图示之:
既然找到了就随意马虎重现了,方法有两类,一类是冒死那个写啊写,尝尝重视现,但这不是我的办法,另一种方法我比较喜好,即故意放大race的条件!
对付本文的场景,我利用jprobe机制故意在1和2之间插入了一个schedule。试着加载包含下面代码的模块:
ssize_t jvfs_write(struct file file, const char __user buf, size_t count, loff_t pos){ if (!strcmp(current->comm, "parent")) { msleep(2000); } jprobe_return(); return 0;}static struct jprobe delay_stub = { .kp = { .symbol_name = "vfs_write", }, .entry = jvfs_write,};
我是HZ1000的机器,上述代码即在1和2之间就寝2秒钟,这样险些可以100%重现问题。
试着跑了一遍,真的就重现了!
文件中有512个字符‘a’,没有看到任何字符‘-‘!
看起来这问题在多CPU机器上是如此地随意马虎重现,以至于任何人都会以为这问题不可能会留到3.10内核还不被修补啊!
但是内核源码摆在那里,确实是有问题啊!
这个时候,我才想起去看一些文档,看看这到底是一个问题呢还是说这本身是合理的,只是须要用户态程序采取某种手段去规避。弯曲之路就不多赘述了,直接man 2 write,看BUGS section:
BUGS According to POSIX.1-2008/SUSv4 Section XSI 2.9.7 ("Thread Interactions with Regular File Operations"): All of the following functions shall be atomic with respect to each other in the effects specified in POSIX.1-2008 when they operate on regular files or symbolic links: ... Among the APIs subsequently listed are write() and writev(2). And among the effects that should be atomic across threads (and processes) are updates of the file offset. However, on Linux before version 3.14, this was not the case: if two processes that share an open file description (see open(2)) perform a write() (or writev(2)) at the same time, then the I/O operations were not atomic with respect updating the file offset, with the result that the blocks of data output by the two processes might (incorrectly) overlap. This problem was fixed in Linux 3.14.
嗯,解释3.10的内核真的是BUG,3.14往后的内核办理了,非常OK!
看了4.14的内核,问题没有了,这问题早就在3.14社区内核中办理:
SYSCALL_DEFINE3(write, unsigned int, fd, const char __user , buf, size_t, count){ struct fd f = fdget_pos(fd); // 这里会锁file的pos锁 ssize_t ret = -EBADF; if (f.file) { loff_t pos = file_pos_read(f.file); ret = vfs_write(f.file, buf, count, &pos); if (ret >= 0) file_pos_write(f.file, pos); fdput_pos(f); } return ret;}
针对该问题的patch解释:
From: Linus Torvalds <torvalds@linux-foundation.org>Date: Mon, 3 Mar 2014 09:36:58 -0800Subject: [PATCH 1/2] vfs: atomic f_pos accesses as per POSIXOur write() system call has always been atomic in the sense that you getthe expected thread-safe contiguous write, but we haven't actuallyguaranteed that concurrent writes are serialized wrt f_pos accesses, sothreads (or processes) that share a file descriptor and use "write()"concurrently would quite likely overwrite each others data.This violates POSIX.1-2008/SUSv4 Section XSI 2.9.7 that says: "2.9.7 Thread Interactions with Regular File Operations All of the following functions shall be atomic with respect to each other in the effects specified in POSIX.1-2008 when they operate on regular files or symbolic links: [...]"and one of the effects is the file position update.This unprotected file position behavior is not new behavior, and nobodyhas ever cared. Until now. Yongzhi Pan reported unexpected behavior toMichael Kerrisk that was due to this.This resolves the issue with a f_pos-specific lock that is taken byread/write/lseek on file descriptors that may be shared across threadsor processes.
一波三折的事情貌似结束了,总结一下收成绩是,碰到问题直接看文档而不是代码估计可能会更快速办理问题。
这绝对是本文的末了一部分,如果再发生故事,我担保会放弃!
由于这个问题本来便是碰到了顺便拿来玩玩的。
当我把机器重启到Centos 2.6.32内核(我认为低版本内核更随意马虎重现,更随意马虎解释问题)时,依然载入我那个jprobe内核模块,运行我那个parent程序,然而并没有重现问题,相反地,当parent被那个msleep壅塞后,child同样也被壅塞了,看样子是修复bug后的行为啊。
第一觉得这可能性不大,毕竟3.10内核都有的问题,2.6.32怎么可能避开?!
然而事后仔细一想,不对,3.10的问题内核是社区内核,2.6.32的是Centos内核,后者会拉取很多的上游patch来办理一些显然的问题的,对付衍生自Redhat公司的稳定版内核,这并不稀奇。
末了,我找到了write的实现:
SYSCALL_DEFINE3(write, unsigned int, fd, const char __user , buf, size_t, count){ struct file file; ssize_t ret = -EBADF; int fput_needed; file = fget_light_pos(fd, &fput_needed); // 这里是关键 if (file) { loff_t pos = file_pos_read(file); ret = vfs_write(file, buf, count, &pos); file_pos_write(file, pos); fput_light_pos(file, fput_needed); } return ret;}
请把稳fget_light_pos是一个新的实现:
struct file fget_light_pos(unsigned int fd, int fput_needed){ struct file file = fget_light(fd, fput_needed); if (file && (file->f_mode & FMODE_ATOMIC_POS)) { if (file_count(file) > 1) { fput_needed |= FDPUT_POS_UNLOCK; // 如果有超过一个进程/线程在操作同一个file,则先lock它!
mutex_lock(&file->f_pos_lock); } } return file;}
事情便是在这里起了变革!
Centos早就拉取了修复该问题的patch,办理了问题便无法重现问题。
以是,社区版内核和发行版内核是完备不同的,侧重点不同吧,社区版内核可能更在意内核本身的子系统以及性能成分,而发行版内核则更看重稳定性以及系统调用,毕竟系统便是用来跑运用的,系统调用作为一个接口,一定要稳定无BUG!















