
正则表达式,或简称RegEx,是可用于文本搜索和更换操作、验证、字符串拆分等的模式表达式。这些模式由字符、数字和分外字符组成,其形式使模式与我们正在搜索的某些文本段相匹配。
正则表达式广泛用于模式匹配,各种编程措辞都有用于表示它们以及与匹配结果交互的接口。

在本文中,我们将看看如何利用正则表达式在Python 中验证电子邮件地址。
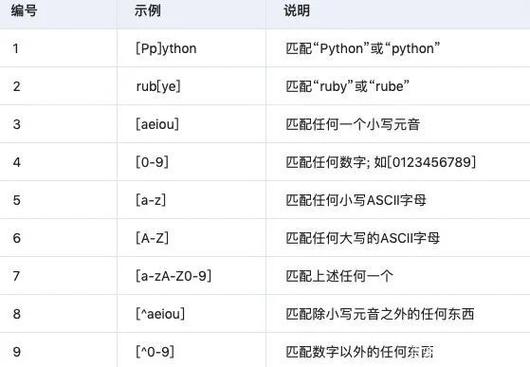
值得把稳的是,没有这样的正则表达式可以匹配每个可能的有效电子邮件地址。虽然,有些表达式可以匹配大多数有效的电子邮件地址。
我们须要定义我们正在探求什么样的电子邮件地址格式。最常见的电子邮件格式是:
#(用户名)@(域名).(顶级域名)(username)@(domainname).(top-leveldomain)
因此,我们可以将其归结为@将前缀与域名分开的符号模式。
该前缀是收件人的姓名-这可能包含大写和小写字母,数字和一些分外字符,如字符串.(点), -(连字符),和_(下划线)。
而域名和顶级域名则由一个.(点符号)划分的。域名可以包含大写和小写字母、数字和-(连字符)符号。此外,顶级域名的长度必须至少为 2 个字符(全部大写或小写)。
大略来说,我们的电子邮件正则表达式可能如下所示:
(string1)@(string2).(2+characters)
这将可以匹配精确的电子邮件地址,例如:
name.surname@gmail.comanonymous123@yahoo.co.ukmy_email@outlook.co
利用相同的表达式,这些电子邮件地址将匹配失落败:
johnsnow@gmailanonymous123@...ukmyemail@outlook.
值得把稳的是,字符串不应包含某些分外字符,以免再次毁坏表单。此外,顶级域不能是... 考虑到这些情形,我们可以将这些规则放入一个详细的表达式中,该表达式考虑了比第一种表示更多的情形:
([A-Za-z0-9]+[.-_])[A-Za-z0-9]+@[A-Za-z0-9-]+(\.[A-Z|a-z]{2,})+
前缀中的分外字符不能恰好位于@符号之前,前缀也不能以它开头,因此我们确保每个分外字符前后至少有一个字母数字字符。
至于域名,一封电子邮件可以包含几个用点分隔的顶级域名。
显然,这个正则表达式比第一个更繁芜,但它涵盖了我们为电子邮件格式定义的所有规则。但是它有可能精确验证一些我们没有想到的边缘情形。
利用 Python 验证电子邮件地址
Python 中的 re 模块可以导入利用Python的正则表达式的类和方法,因此我们将其导入到我们的脚本中。我们将利用的方法是re.fullmatch(pattern, string, flags)。仅当全体字符串与模式匹配时,此方法才返回匹配工具,在其他情形下,它都返回None。
把稳: re.fullmatch()在 Python 3.4 中引入,在此之前,re.match()改为利用。在较新的版本上,fullmatch()首选。
让我们compile()函数利用前面的正则表达式,并定义一个大略的函数来接管电子邮件地址并利用该表达式来验证它:
import reregex = re.compile(r'([A-Za-z0-9]+[.-_])[A-Za-z0-9]+@[A-Za-z0-9-]+(\.[A-Z|a-z]{2,})+')def isValid(email): if re.fullmatch(regex, email): print("有效的email地址") else: print("无效的email地址")re.compile()方法将正则表达式模式编译为正则表达式工具。
现在,让我们在之前看过的一些示例上测试代码:
isValid("name.surname@gmail.com")isValid("anonymous123@yahoo.co.uk")isValid("anonymous123@...uk")isValid("...@domain.us")输出:
有效的email地址有效的email地址无效的email地址无效的email地址太棒了,我们有了一个正常运行的邮件地址校验系统!
更为强大的电子邮件正则表达式我们上面利用的表达式适用于大多数情形,并且适用于任何合理的运用程序。但是,如果安全性受到更高的关注,或者如果您喜好编写正则表达式,您可以选择收紧可能性的范围,同时仍旧许可有效的电子邮件地址通过。
更长表达式每每会变得有点繁芜且难以阅读,这个表达式也不例外:
(?:[a-z0-9!#$%&'+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'+/=^_`{|}~-]+)|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])")@(?:(?:[a-z0-9](?:[a-z0-9-][a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-][a-z0-9])?|\[(?:(?:(2(5[0-5]|[0-4][0-9])|1[0-9][0-9]|[1-9]?[0-9]))\.){3}(?:(2(5[0-5]|[0-4][0-9])|1[0-9][0-9]|[1-9]?[0-9])|[a-z0-9-][a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])下图是符合RFC5322的正则表达式,涵盖了 99.99% 的输入电子邮件地址。 用笔墨来阐明它常日是比较困难的,但可以通过图片大致理解它:
结论Python中利用正则表达式验证电子邮件的方法有很多种,紧张取决于我们判断探求邮件的特定格式。同时,没有一种独特的正则表达式模式适用于所有电子邮件格式,我们只须要定义邮件规则,并相应地构建适宜的正则表达式匹配模式。















