
网络爬虫是获取数据的关键技能,它在信息搜集和数据剖析等多个领域发挥着重要浸染。在这篇文章中,我们将通过浩瀚详尽的代码实例,向您展示如何利用Python措辞打造一套功能完备的网络爬虫办理方案,包括数据的采集、净化、保存和剖析等环节。我们期望读者通过本文能够学会自主构建网络爬虫系统的关键技巧。
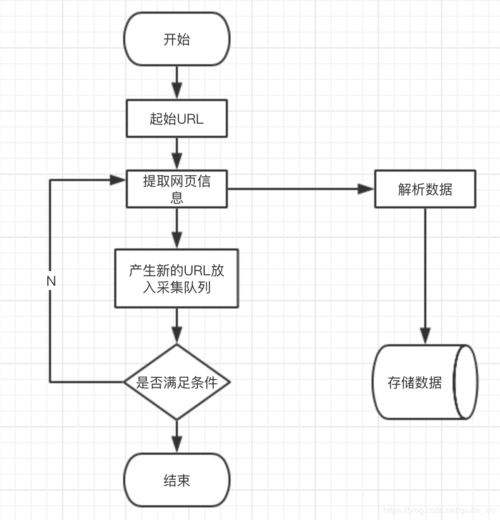
一、网络爬虫根本观点与环境准备网络爬虫是一种自动化程序,通过仿照浏览器访问网页并提取有用信息。我们将利用requests和BeautifulSoup库来实现爬虫功能。

1. 安装必要的Python库
首先,我们须要安装一些常用的库,运行以下命令即可:
bash
复制代码
pip install requests beautifulsoup4 pandas
二、构建根本网络爬虫我们将从一个大略的爬虫开始,抓取网页内容并解析个中的数据。
1. 利用requests获取网页内容
requests库可以轻松发送HTTP要求并获取相应内容。
python
复制代码
import requests
# 设置目标URL
url = 'https://example.com'
# 发送GET要求获取网页内容
response = requests.get(url)
# 检讨相应状态
if response.status_code == 200:
print("成功获取网页内容!
")
print(response.text)
else:
print("要求失落败,状态码:", response.status_code)
2. 利用BeautifulSoup解析网页
BeautifulSoup库可以方便地解析HTML内容,提取网页中的信息。
python
复制代码
from bs4 import BeautifulSoup
www.yunduaner.com/ulR8x7/
# 利用BeautifulSoup解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
# 提取网页标题
title = soup.find('title').get_text()
print("网页标题:", title)
# 提取所有链接
links = soup.find_all('a')
for link in links:
print(link.get('href'))
三、批量抓取与数据处理实际运用中,常日须要从多个网页获取数据并进行处理。
1. 批量抓取网页数据
我们可以遍历多个URL,批量抓取数据并存储在列表中。
python
复制代码
data = []
# 要抓取的多个URL
urls = ['https://example.com/page1', 'https://example.com/page2', 'https://example.com/page3']
for url in urls:
www.yuanyets.com/S3mJN8/
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.find('title').get_text()
data.append(title)
print("抓取的数据:", data)
2. 数据洗濯与处理
利用pandas库对抓取的数据进行洗濯和处理。
python
复制代码
import pandas as pd
# 转换为DataFrame
df = pd.DataFrame(data, columns=['Title'])
# 去除重复数据
df.drop_duplicates(inplace=True)
# 打印洗濯后的数据
print("洗濯后的数据:")
print(df)
四、数据存储与读取为了便于数据管理,我们将抓取的数据存储到数据库中。
1. 利用SQLite存储数据
SQLite是轻量级的数据库,适宜小规模数据的存储。
python
复制代码
import sqlite3
# 连接SQLite数据库
conn = sqlite3.connect('data.db')
c = conn.cursor()
# 创建表格
c.execute('''
CREATE TABLE IF NOT EXISTS webpage (
id INTEGER PRIMARY KEY,
title TEXT
''')
# 插入数据
for index, row in df.iterrows():
c.execute('INSERT INTO webpage (title) VALUES (?)', (row['Title'],))
# 提交事务
conn.commit()
# 关闭连接
conn.close()
2. 从数据库中读取数据
python
复制代码
# 连接数据库
conn = sqlite3.connect('data.db')
c = conn.cursor()
# 查询数据
c.execute('SELECT FROM webpage')
rows = c.fetchall()
# 打印查询结果
for row in rows:
print(row)
# 关闭连接
conn.close()
五、数据剖析与可视化抓取到的数据可以进行剖析和可视化,以便从中挖掘有用的信息。
1. 数据统计剖析
利用pandas库进行数据统计剖析。
python
复制代码
# 连接数据库
conn = sqlite3.connect('data.db')
# 利用pandas读取数据
df = pd.read_sql_query('SELECT FROM webpage', conn)
# 数据描述统计
print("数据描述统计:")
print(df.describe())
# 关闭连接
conn.close()
2. 数据可视化
利用matplotlib库进行数据可视化。
python
复制代码
import matplotlib.pyplot as plt
# 添加列表示标题长度
df['title_length'] = df['title'].apply(len)
# 绘制标题长度分布直方图
plt.figure(figsize=(10, 6))
plt.hist(df['title_length'], bins=20, edgecolor='black')
plt.xlabel('标题长度')
plt.ylabel('频数')
plt.title('标题长度分布')
plt.show()
六、提高爬虫效率与应对反爬虫方法为了提高爬虫效率和应对反爬虫方法,我们可以采纳一些技能手段。
1. 利用多线程提高效率
利用threading库实现多线程爬虫。
python
复制代码
import threading
def fetch_data(url):
www.xsjdyp.com/JZGO8k/
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.find('title').get_text()
print(f"从 {url} 获取的数据:{title}")
# 要抓取的URL列表
urls = ['https://example.com/page1', 'https://example.com/page2', 'https://example.com/page3']
# 创建线程
threads = []
for url in urls:
thread = threading.Thread(target=fetch_data, args=(url,))
threads.append(thread)
thread.start()
# 等待所有线程完成
for thread in threads:
thread.join()
2. 应对反爬虫机制
应对常见的反爬虫方法如IP封禁和验证码。
python
复制代码
import time
# 设置要求头,仿照浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
# 利用代理进行要求
proxies = {
'http': 'http://your_proxy:port',
'https': 'https://your_proxy:port'
}
# 发送要求
response = requests.get(url, headers=headers, proxies=proxies)
# 设置延迟,避免触发反爬虫
time.sleep(2)
七、总结与展望本文通过详细的代码示例,展示了如何利用Python从数据抓取、洗濯、存储到剖析,构建一个完全的网络爬虫系统。希望读者能够节制从零开始搭建网络爬虫的核心技能,并通过不断学习,提升数据采集和剖析能力,欢迎未来的寻衅。无限超人,8年数据领域深耕,专注于精准数据采集与智能RPA,开释数据潜能,提升业务效率。















