
来自:张狗蛋的技能之路
Redis是一个开源的 key-value 存储系统,它利用六种底层数据构造构建了包含字符串工具、列表工具、哈希工具、凑集工具和有序凑集工具的工具系统。本日我们就通过12张图来全面理解一下它的数据构造和工具系统的实现事理。

本文的内容如下:
大略动态字符串
Redis 利用动态字符串 SDS 来表示字符串值。下图展示了一个值为 Redis 的 SDS构造 :
len: 表示字符串的真正长度(不包含NULL结束符在内)。alloc: 表示字符串的最大容量(不包含末了多余的那个字节)。flags: 总是占用一个字节。个中的最低3个bit用来表示header的类型。buf: 字符数组。SDS 的构造可以减少修正字符串时带来的内存重分配的次数,这依赖于内存预分配和惰性空间开释两大机制。
当 SDS 须要被修正,并且要对 SDS 进行空间扩展时,Redis 不仅会为 SDS 分配修正所必须要的空间,还会为 SDS 分配额外的未利用的空间。
如果修正后, SDS 的长度(也便是len属性的值)将小于 1MB ,那么 Redis 预分配和 len 属性相同大小的未利用空间。如果修正后, SDS 的长度将大于 1MB ,那么 Redis 会分配 1MB 的未利用空间。比如说,进行修正后 SDS 的 len 长度为20字节,小于 1MB,那么 Redis 会预先再分配 20 字节的空间, SDS 的 buf数组的实际长度(撤除末了一字节)变为 20 + 20 = 40 字节。当 SDS的 len 长度大于 1MB时,则只会再多分配 1MB的空间。
类似的,当 SDS 缩短其保存的字符串长度时,并不会立即开释多出来的字节,而是等待之后利用。
链表
链表在 Redis 中的运用非常广泛,比如列表工具的底层实现之一便是链表。除了链表工具外,发布和订阅、慢查询、监视器等功能也用到了链表。
Redis 的链表是双向链表,示意图如上图所示。链表是最为常见的数据构造,这里就不在细说。
Redis 的链表构造的dup 、 free 和 match 成员属性是用于实现多态链表所需的类型特定函数:
dup 函数用于复制链表节点所保存的值,用于深度拷贝。free 函数用于开释链表节点所保存的值。match 函数则用于比拟链表节点所保存的值和另一个输入值是否相等。字典
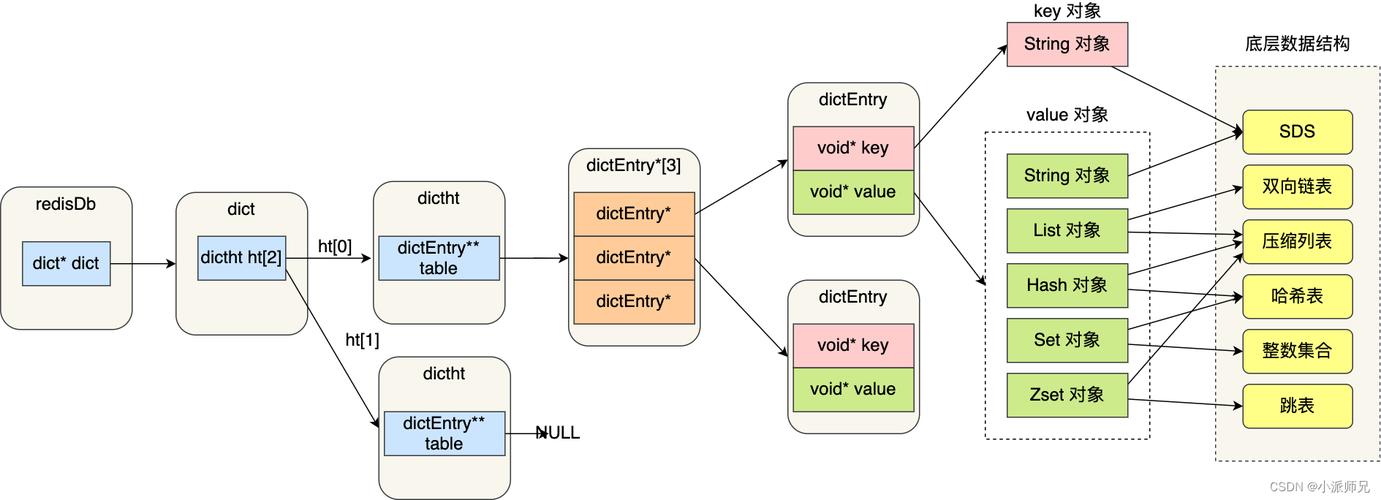
字典被广泛用于实现 Redis 的各种功能,包括键空间和哈希工具。其示意图如下所示。
Redis 利用 MurmurHash2 算法来打算键的哈希值,并且利用链地址法来办理键冲突,被分配到同一个索引的多个键值对会连接成一个单向链表。
跳跃表
Redis 利用跳跃表作为有序凑集工具的底层实现之一。它以有序的办法在层次化的链表中保存元素, 效率和平衡树媲美 —— 查找、删除、添加等操作都可以在对数期望韶光下完成, 并且比起平衡树来说, 跳跃表的实现要大略直不雅观得多。
跳表的示意图如上图所示,这里只大略说一下它的核心思想,并不进行详细的阐明。
如示意图所示,zskiplistNode 是跳跃表的节点,其 ele 是保持的元素值,score 是分值,节点按照其 score 值进行有序排列,而 level 数组便是其所谓的层次化链表的表示。
每个 node 的 level 数组大小都不同, level 数组中的值是指向下一个 node 的指针和 跨度值 (span),跨度值是两个节点的score的差值。越高层的 level 数组值的跨度值就越大,底层的 level 数组值的跨度值越小。
level 数组就像是不同刻度的尺子。度量长度时,先用大刻度估计范围,再不断地用缩小刻度,进行精确逼近。
当在跳跃表中查询一个元素值时,都先从第一个节点的最顶层的 level 开始。比如说,在上图的跳表中查询 o2 元素时,先从o1 的节点开始,由于 zskiplist 的 header 指针指向它。
先从其 level[3] 开始查询,创造其跨度是 2,o1 节点的 score 是1.0,以是加起来为 3.0,大于 o2 的 score 值2.0。以是,我们可以知道 o2 节点在 o1 和 o3 节点之间。这时,就改用小刻度的尺子了。就用level[1]的指针,顺利找到 o2 节点。
整数凑集
整数凑集 intset 是凑集工具的底层实现之一,当一个凑集只包含整数值元素,并且这个凑集的元素数量不多时, Redis 就会利用整数凑集作为凑集工具的底层实现。
如上图所示,整数凑集的 encoding 表示它的类型,有int16t,int32t 或者int64_t。其每个元素都是 contents 数组的一个数组项,各个项在数组中按值的大小从小到大有序的排列,并且数组中不包含任何重复项。length 属性便是整数凑集包含的元素数量。
压缩列表
压缩行列步队 ziplist 是列表工具和哈希工具的底层实现之一。当知足一定条件时,列表工具和哈希工具都会以压缩行列步队为底层实现。
压缩行列步队是 Redis 为了节约内存而开拓的,是由一系列分外编码的连续内存块组成的顺序型数据构造。它的属性值有:
zlbytes : 长度为 4 字节,记录全体压缩数组的内存字节数。zltail : 长度为 4 字节,记录压缩行列步队表尾节点间隔压缩行列步队的起始地址有多少字节,通过该属性可以直接确定尾节点的地址。zllen : 长度为 2 字节,包含的节点数。当属性值小于 INT16_MAX时,该值便是节点总数,否则须要遍历全体行列步队才能确定总数。zlend : 长度为 1 字节,分外值,用于标记压缩行列步队的末端。中间每个节点 entry 由三部分组成:
previous_entry_length : 压缩列表中前一个节点的长度,和当前的地址进行指针运算,打算出前一个节点的起始地址。encoding: 节点保存数据的类型和长度content :节点值,可以为一个字节数组或者整数。工具
上面先容了 6 种底层数据构造,Redis 并没有直策应用这些数据构造来实现键值数据库,而是基于这些数据构造创建了一个工具系统,这个别系包含字符串工具、列表工具、哈希工具、凑集工具和有序凑集这五种类型的工具,每个工具都利用到了至少一种前边讲的底层数据构造。
Redis 根据不同的利用场景和内容大小来判断工具利用哪种数据构造,从而优化工具在不同场景下的利用效率和内存占用。
Redis 的 redisObject 构造的定义如下所示。
个中 type 是工具类型,包括REDISSTRING, REDISLIST, REDISHASH, REDISSET 和 REDIS_ZSET。
encoding是指工具利用的数据构造,全集如下。
字符串工具
我们首先来看字符串工具的实现,如下图所示。
如果一个字符串工具保存的是一个字符串值,并且长度大于32字节,那么该字符串工具将利用 SDS 进行保存,并将工具的编码设置为 raw,如图的上半部分所示。如果字符串的长度小于32字节,那么字符串工具将利用embstr 编码办法来保存。
embstr 编码是专门用于保存短字符串的一种优化编码办法,这个编码的组成和 raw 编码同等,都利用 redisObject 构造和 sdshdr 构造来保存字符串,如上图的下半部所示。
但是 raw 编码会调用两次内存分配来分别创建上述两个构造,而 embstr 则通过一次内存分配来分配一块连续的空间,空间中一次包含两个构造。
embstr 只需一次内存分配,而且在同一块连续的内存中,更好的利用缓存带来的上风,但是 embstr 是只读的,不能进行修正,当一个 embstr 编码的字符串工具进行 append 操作时, redis 会现将其转变为 raw 编码再进行操作。
列表工具
列表工具的编码可以是 ziplist 或 linkedlist。其示意图如下所示。
当列表工具可以同时知足以下两个条件时,列表工具利用 ziplist 编码:
列表工具保存的所有字符串元素的长度都小于 64 字节。列表工具保存的元素数量数量小于 512 个。不能知足这两个条件的列表工具须要利用 linkedlist 编码或者转换为 linkedlist 编码。
哈希工具
哈希工具的编码可以利用 ziplist 或 dict。其示意图如下所示。
当哈希工具利用压缩行列步队作为底层实现时,程序将键值对紧挨着插入到压缩行列步队中,保存键的节点在前,保存值的节点在后。如下图的上半部分所示,该哈希有两个键值对,分别是 name:Tom 和 age:25。
当哈希工具可以同时知足以下两个条件时,哈希工具利用 ziplist 编码:
哈希工具保存的所有键值对的键和值的字符串长度都小于64字节。哈希工具保存的键值对数量小于512个。不能知足这两个条件的哈希工具须要利用 dict 编码或者转换为 dict 编码。
凑集工具
凑集工具的编码可以利用 intset 或者 dict。
intset 编码的凑集工具利用整数凑集最为底层实现,所有元素都被保存在整数凑集里边。
而利用 dict 进行编码时,字典的每一个键都是一个字符串工具,每个字符串工具便是一个凑集元素,而字典的值全部都被设置为NULL。如下图所示。
当凑集工具可以同时知足以下两个条件时,工具利用 intset 编码:
凑集工具保存的所有元素都是整数值。凑集工具保存的元素数量不超过512个。否则利用 dict 进行编码。
有序凑集工具
有序凑集的编码可以为 ziplist 或者 skiplist。
有序凑集利用 ziplist 编码时,每个凑集元素利用两个紧挨在一起的压缩列表节点表示,前一个节点是元素的值,第二个节点是元素的分值,也便是排序比较的数值。
压缩列表内的凑集元素按照分值从小到大进行排序,如下图上半部分所示。
有序凑集利用 skiplist 编码时利用 zset 构做作为底层实现,一个 zet 构造同时包含一个字典和一个跳跃表。
个中,跳跃表按照分值从小到大保存所有元素,每个跳跃表节点保存一个元素,其score值是元素的分值。而字典则创建一个一个从成员到分值的映射,字典的键是凑集成员的值,字典的值是凑集成员的分值。通过字典可以在O(1)繁芜度查找给定成员的分值。如下图所示。
跳跃表和字典中的凑集元素值工具都是共享的,以是不会额外花费内存。
当有序凑集工具可以同时知足以下两个条件时,工具利用 ziplist 编码:
有序凑集保存的元素数量少于128个;有序凑集保存的所有元素的长度都小于64字节。否则利用 skiplist 编码。
数据库键空间Redis 做事器都有多个 Redis 数据库,每个Redis 数据都有自己独立的键值空间。每个 Redis 数据库利用 dict 保存数据库中所有的键值对。
键空间的键也便是数据库的键,每个键都是一个字符串工具,而值工具可能为字符串工具、列表工具、哈希表工具、凑集工具和有序凑集工具中的一种工具。
除了键空间,Redis 也利用 dict 构造来保存键的过期韶光,其键是键空间中的键值,而值是过期韶光,如上图所示。
通过过期字典,Redis 可以直接判断一个键是否过期,首先查看该键是否存在于过期字典,如果存在,则比较该键的过期韶光和当前做事器韶光戳,如果大于,则该键过期,否则未过期。















