
NoSql,叫非关系型数据库,它的全名Not only sql。它不能替代关系型数据库,只能作为关系型数据库的一个良好补充。
Nosql 分类键值(Key-Value)存储数据库 干系产品: Tokyo Cabinet/Tyrant、Redis、Voldemort、Berkeley DB 范例运用: 内容缓存,紧张用于处理大量数据的高访问负载。 数据模型: 一系列键值对 上风: 快速查询 劣势: 存储的数据短缺构造化列存储数据库 干系产品:Cassandra, HBase, Riak 范例运用:分布式的文件系统 数据模型:以列簇式存储,将同一列数据存在一起 上风:查找速率快,可扩展性强,更随意马虎进行分布式扩展 劣势:功能相对局限文档型数据库 干系产品:CouchDB、MongoDB 范例运用:Web运用(与Key-Value类似,Value是构造化的) 数据模型: 一系列键值对 上风:数据构造哀求不严格 劣势: 查询性能不高,而且缺少统一的查询语法图形(Graph)数据库 干系数据库:Neo4J、InfoGrid、Infinite Graph 范例运用:社交网络 数据模型:图构造 上风:利用图构造干系算法。 劣势:须要对全体图做打算才能得出结果,不随意马虎做分布式的集群方案。Redis 基本观点Redis是利用c措辞开拓的一个高性能键值数据库。Redis可以通过一些键值类型来存储数据。 键值类型: String字符类型 map散列类型 list列表类型 set凑集类型 sortedset有序凑集类型

2008年,意大利的一家创业公司Merzia推出了一款基于MySQL的网站实时统计系统LLOOGG,然而没过多久该公司的创始人 Salvatore Sanfilippo便 对MySQL的性能感到失落望,于是他决定亲自为LLOOGG量身定做一个数据库,并于2009年开拓完成,这个数据库便是Redis。 不过Salvatore Sanfilippo并不知足只将Redis用于LLOOGG这一款产品,而是希望更多的人利用它,于是在同一年Salvatore Sanfilippo将Redis开源发布,并开始和Redis的另一名紧张的代码贡献者Pieter Noordhuis一起连续着Redis的开拓,直到本日。
Salvatore Sanfilippo自己也没有想到,短短的几年韶光,Redis就拥有了弘大的用户群体。Hacker News在2012年发布了一份数据库的利用情形调查,结果显示有近12%的公司在利用Redis。海内如新浪微博、街旁网、知乎网,国外如GitHub、Stack Overflow、Flickr等都是Redis的用户。
VMware公司从2010年开始资助Redis的开拓, Salvatore Sanfilippo和Pieter Noordhuis也分别在3月和5月加入VMware,全职开拓Redis。
运用处景缓存(数据查询、短连接、新闻内容、商品内容等等)。(最多利用) 分布式集群架构中的session分离。 谈天室的在线好友列表。 任务行列步队。(秒杀、抢购、12306等等) 运用排行榜。 网站访问统计。 数据过期处理(可以精确到毫秒)
2 Redis 安装下载官网地址:http://redis.io/ 下载地址:http://download.redis.io/releases/redis-3.0.0.tar.gz
安装#sftp 上传安装包到linux#解压tar -zxvf redis.3.0.0.tar.gz#安装c措辞环境sudo apt-get install gcc-c++#编译cd redis-3.0.0make#安装make install PREFIX = /usr/local/redis# 查看cd /usr/local/redislsredis 启动前端启动前端启动命令 ./redis-server前端启动的关闭 逼迫关闭 ctrl+c 正常关闭 ./redis-cli shutdown
tips:一旦客户端关闭,则redis做事也会停掉
后端启动将 redis 源码包中的 redis.conf 文件拷贝至 bin 目录下 cp /root/redis-3.0.0/redis.conf修正 redis.conf 文件,将 daemonize 改为 yes vim redis.conf利用后端命令启动 redis ./redis-server redis.conf查看是否启动成功 ps -aux | grep redis关闭后端启动的办法 逼迫关闭: kill -9 进程号 正常关闭:./redis-cli shutdown3 Redis 客户端自带客户端启动 ./redis-cli -h 127.0.0.1 -p 6379 -h 指定访问 redis 做事器的 ip 地址 -p 指定访问的 redis 做事器的 port 端口 还可以写成 ./redis-cli 利用默认配置,默认ip 127.0.0.1,默认端口 6379关闭 ctrl + c 127.0.0.1:6379>quit图形界面客户端redis-desktop-manager 打开如下:
选择数据库办法: select 加上数据库的下标,就可以选择指定的数据库利用,下标从0开始。
127.0.0.1:6379> select 15OK127.0.0.1:6379[15]>jedis 客户端先容
Redis不仅是利用命令来操作,现在基本上主流的措辞都有客户端支持,比如java、C、C#、C++、php、Node.js、Go等。
在官方网站里列一些Java的客户端,有Jedis、Redisson、Jredis、JDBC-Redis、等个中官方推举利用Jedis和Redisson。 在企业中用的最多的便是Jedis,下面我们就重点学习下Jedis。
Jedis同样也是托管在github上,地址:https://github.com/xetorthio/jedis
工程搭建添加 jar commons-pool2-2.3.jar jedis-2.7.0.jar单例连接redis利用连接池连接 redis
Spring 整合 jedisPool
添加 spring 的 jar 包 配置 spring 配置文件 applicationContext.xml
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:mvc="http://www.springframework.org/schema/mvc" xmlns:context="http://www.springframework.org/schema/context" xmlns:aop="http://www.springframework.org/schema/aop" xmlns:tx="http://www.springframework.org/schema/tx" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.2.xsd http://www.springframework.org/schema/mvc http://www.springframework.org/schema/mvc/spring-mvc-3.2.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.2.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-3.2.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-3.2.xsd "> <!-- 连接池配置 --> <bean id="jedisPoolConfig" class="redis.clients.jedis.JedisPoolConfig"> <!-- 最大连接数 --> <property name="maxTotal" value="30" /> <!-- 最大空闲连接数 --> <property name="maxIdle" value="10" /> <!-- 每次开释连接的最大数目 --> <property name="numTestsPerEvictionRun" value="1024" /> <!-- 开释连接的扫描间隔(毫秒) --> <property name="timeBetweenEvictionRunsMillis" value="30000" /> <!-- 连接最小空闲韶光 --> <property name="minEvictableIdleTimeMillis" value="1800000" /> <!-- 连接空闲多久后开释, 当空闲韶光>该值 且 空闲连接>最大空闲连接数 时直接开释 --> <property name="softMinEvictableIdleTimeMillis" value="10000" /> <!-- 获取连接时的最大等待毫秒数,小于零:壅塞不愿定的韶光,默认-1 --> <property name="maxWaitMillis" value="1500" /> <!-- 在获取连接的时候检讨有效性, 默认false --> <property name="testOnBorrow" value="false" /> <!-- 在空闲时检讨有效性, 默认false --> <property name="testWhileIdle" value="true" /> <!-- 连接耗尽时是否壅塞, false报非常,ture壅塞直到超时, 默认true --> <property name="blockWhenExhausted" value="false" /> </bean> <!-- redis单机 通过连接池 --> <bean id="jedisPool" class="redis.clients.jedis.JedisPool" destroy-method="close"> <constructor-arg name="poolConfig" ref="jedisPoolConfig" /> <constructor-arg name="host" value="192.168.242.130" /> <constructor-arg name="port" value="6379" /> </bean></beans>
测试代码
@Test public void testJedisPool() { JedisPool pool = (JedisPool) applicationContext.getBean("jedisPool"); Jedis jedis = null; try { jedis = pool.getResource(); jedis.set("name", "lisi"); String name = jedis.get("name"); System.out.println(name); } catch (Exception ex) { ex.printStackTrace(); } finally { if (jedis != null) { // 关闭连接 jedis.close(); } } }4 数据类型String 类型
赋值 set key value
127.0.0.1:6379> set test 123OK
取值 get key
127.0.0.1:6379> get test"123"
取值并赋值 getset key value
127.0.0.1:6379> getset test 321"123"127.0.0.1:6379> get test"321"
设置获取多个键值 mset key value [key value...] mget key [key...]
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3OK127.0.0.1:6379> mget k1 k21) "v1"2) "v2"
删除 del key
127.0.0.1:6379> del test(integer) 1
数值增减
递增数字 当存储的字符串是整数时,Redis供应了一个实用的命令INCR,其浸染是让当前键值递增,并返回递增后的值。 语法:incr key127.0.0.1:6379> set num 1OK127.0.0.1:6379> incr num(integer) 2127.0.0.1:6379> incr num(integer) 3127.0.0.1:6379> incr num(integer) 4增加指定的整数 incrby key increment
127.0.0.1:6379> incrby num 2(integer) 8127.0.0.1:6379> incrby num 2(integer) 10递减数值 decr key
127.0.0.1:6379> decr num(integer) 9127.0.0.1:6379> decr num(integer) 8减少指定的数值 decryby key decrement
127.0.0.1:6379> decr num(integer) 9127.0.0.1:6379> decr num(integer) 8
向尾部追加值 APPEND的浸染是向键值的末端追加value。如果键不存在则将该键的值设置为value,即相称于 SET key value。返回值是追加后字符串的总长度。 语法:append key value
127.0.0.1:6379> set str helloOK127.0.0.1:6379> append str "world"(integer) 10127.0.0.1:6379> get str"helloworld"
获取字符串长度 STRLEN命令返回键值的长度,如果键不存在则返回0。 语法:strlen key
127.0.0.1:6379> strlen str(integer) 10
运用
自增主键 商品编号、订单号采取 string 的递增数字特性天生Hash 散列类型利用 string 的问题假设有User工具以JSON序列化的形式存储到Redis中,User工具有id,username、password、age、name等属性,存储的过程如下: 保存、更新:User工具 json(string) redis
如果在业务上只是更新age属性,其他的属性并不做更新我该当怎么做呢? 如果仍旧采取上边的方法在传输、处理时会造成资源摧残浪费蹂躏,下边讲的hash可以很好的办理这个问题。
先容hash叫散列类型,它供应了字段和字段值的映射。字段值只能是字符串类型,不支持散列类型、凑集类型等其它类型。如下:
命令
赋值 HSET命令不区分插入和更新操作,当实行插入操作时HSET命令返回1,当实行更新操作时返回0。
一次只设置一个字段值 语法:hset key field value127.0.0.1:6379> hset user username zhangsan(integer) 1一次设置多个字段值 语法:hmset key field value [field value...]
127.0.0.1:6379> hmset user age 20 username lisiOK当字段不存在时赋值,类似hset,差异在于如果字段存在,该命令不实行任何操作。 语法:hsetnx key field value
127.0.0.1:6379> hsetnx user age 30(integer) 0
取值
一次获取一个字段值 语法:hget key field127.0.0.1:6379> hget user username"lisi"一次可以获取多个字段值 语法:hmget key field [field...]
127.0.0.1:6379> hmget user age username1) "20"2) "lisi"获取所有字段值 语法:hgetall key
127.0.0.1:6379> hgetall user1) "username"2) "lisi"3) "age"4) "20"
删除字段 可以删除一个或多个字段,返回值是被删除的字段的个数。 语法:hdel key field [field...]
127.0.0.1:6379> hdel user age(integer) 1127.0.0.1:6379> hdel user age username(integer) 1
增加数字 语法:hincrby key field increment
127.0.0.1:6379> hincrby user age 2(integer) 2
判断字段是否存在 语法:hexists key field
127.0.0.1:6379> hexists user age(integer) 1
只获取字段名或字段值 语法: hkeys key hvals key
127.0.0.1:6379> hkeys user1) "age"
获取字段数量 语法:hlen key
127.0.0.1:6379> hlen user(integer) 1
运用 存储商品信息
127.0.0.1:6379> hgetall items:10011) "id"2) "3"3) "name"4) "apple"5) "price"6) "5.00"
获取商品信息
127.0.0.1:6379> hgetall items:10011) "id"2) "3"3) "name"4) "apple"5) "price"6) "5.00"List 类型ArrayList 和 LinkedList 的差异
Arraylist是利用数组来存储数据,特点:查询快、增删慢
Linkedlist是利用双向链表存储数据,特点:增删快、查询慢,但是查询链表两端的数据也很快。
Redis的list是采取来链表来存储的,以是对付redis的list数据类型的操作,是操作list的两端数据来操作的。
命令向列表两端增加元素
向列表左边增加元素 语法:lpush key value [value...]127.0.0.1:6379> lpush list:1 1 2 3(integer) 3向列表右边增加元素 语法:rpush key value [value...]
127.0.0.1:6379> rpush list:1 4 5 6(integer) 6
查看列表 LRANGE命令是列表类型最常用的命令之一,获取列表中的某一片段,将返回start、stop之间的所有元素(包含两端的元素),索引从0开始。索引可以是负数,如:“-1”代表末了边的一个元素。
语法:lrange key start stop
127.0.0.1:6379> lrange list:1 0 21) "3"2) "2"3) "1"127.0.0.1:6379> lrange list:1 0 -11) "3"2) "2"3) "1"4) "4"5) "5"6) "6"
从列表两端弹出元素 LPOP命令从列表左边弹出一个元素,会分两步完成:
第一步是将列表左边的元素从列表中移除第二步是返回被移除的元素值。 语法: lpop key rpop key127.0.0.1:6379> lpop list:1 "3" 127.0.0.1:6379> rpop list:1 "6" 复制代码获取列表中元素的个数 语法:llen key
127.0.0.1:6379> llen list:1(integer) 4
删除列表中指定的值 LREM命令会删除列表中前count个值为value的元素,返回实际删除的元素个数。根据count值的不同,该命令的实行办法会有所不同:
当count>0时, LREM会从列表左边开始删除。当count<0时, LREM会从列表后边开始删除。当count=0时, LREM删除所有值为value的元素。语法:lrem key count value
得到/设置指定索引的元素值
得到指定索引的元素值 语法:lindex key index127.0.0.1:6379> lindex list:1 2 "4" 复制代码设置指定索引的元素值 语法:lset key index value127.0.0.1:6379> lset list:1 2 2 OK 复制代码只保留列表指定片段 指定例模和 lrange 同等 语法:ltrim key start stop
127.0.0.1:6379> lrange list:1 0 -11) "2"2) "1"3) "2"4) "5"127.0.0.1:6379> ltrim list:1 0 2OK127.0.0.1:6379> lrange list:1 0 -11) "2"2) "1"3) "2"
向列表中插入元素 该命令首先会在列表中从左到右查找值为pivot的元素,然后根据第二个参数是BEFORE还是AFTER来决定将value插入到该元素的前面还是后面。 语法:linsert key before | after pivot value
127.0.0.1:6379> lrange list:1 0 -11) "2"2) "1"3) "2"127.0.0.1:6379> linsert list:1 after 1 9(integer) 4127.0.0.1:6379> lrange list:1 0 -11) "2"2) "1"3) "9"4) "2"
将元素从一个列表转移到另一个列表 语法:rpoplpush source destination
127.0.0.1:6379> lrange list:1 0 -11) "2"2) "1"3) "9"4) "2"127.0.0.1:6379> rpoplpush list:1 newlist"2"127.0.0.1:6379> lrange newlist 0 -11) "2"127.0.0.1:6379> lrange list:1 0 -11) "2"2) "1"3) "9"
运用 在Redis中创建商批驳论列表 用户发布商批驳论,将评论信息转成json存储到list中。 用户在页面查询评论列表,从redis中取出json数据展示到页面。
定义商批驳论列表key: 商品编号为1001的商批驳论key【items: comment:1001】
Set 类型凑集类型:无序、不可重复 列表类型:有序、可重复
命令增加/删除元素 语法:sadd key member [member...]
127.0.0.1:6379> sadd set a b c(integer) 3127.0.0.1:6379> sadd set a(integer) 0
语法:srem key member [member...]
127.0.0.1:6379> srem set c(integer) 1
得到凑集中的所有元素 语法:smembers key
127.0.0.1:6379> smembers set1) "b"2) "a"
判断元素是否在凑集中 语法:sismember key member
127.0.0.1:6379> sismember set a(integer) 1127.0.0.1:6379> sismember set h(integer) 0运算命令
凑集的差集运算 A-B 属于 A 并且 不属于 B 的元素构成的凑集
语法:sdiff key [key...]
127.0.0.1:6379> sadd setA 1 2 3(integer) 3127.0.0.1:6379> sadd setB 2 3 4(integer) 3127.0.0.1:6379> sdiff setA setB 1) "1"127.0.0.1:6379> sdiff setB setA1) "4"
凑集的交集运算 属于A且属于B的元素构成的凑集
语法:sinter key [key...]
127.0.0.1:6379> sunion setA setB1) "1"2) "2"3) "3"4) "4"
凑集的并集运算 属于 A 或者 属于 B 的元素构成的凑集
语法:sunion key [key...]
127.0.0.1:6379> smembers setA1) "1"2) "2"3) "3"127.0.0.1:6379> scard setA(integer) 3
得到凑集中元素的个数 语法:scard key
127.0.0.1:6379> spop setA"2"
从凑集中弹出一个元素 把稳:由于凑集是无序的,所有spop命令会从凑集中随机选择一个元素弹出。 语法:spop key
127.0.0.1:6379> spop setA"2"Sortedset 类型
Sortedset 又叫 zset Sortedset 是有序凑集,可排序的,但是唯一。 Sortedset 和 set 的不同之处,会给 set 中元素添加一个分数,然后通过这个分数进行排序。
命令增加元素向有序凑集中加入一个元素和该元素的分数,如果该元素已经存在则会用新的分数更换原有的分数。返回值是新加入到凑集中的元素个数,不包含之前已经存在的元素。 语法:zadd key score member [score member...]
127.0.0.1:6379> zadd scoreboard 80 zhangsan 89 lisi 94 wangwu(integer) 3127.0.0.1:6379> zadd scoreboard 97 lisi(integer) 0获取元素分数
语法:zscore key member
127.0.0.1:6379> zscore scoreboard lisi"97"删除元素
移除有序集key中的一个或多个成员,不存在的成员将被忽略。 当key存在但不是有序集类型时,返回一个缺点。
语法:zrem key member [member...]
127.0.0.1:6379> zrem scoreboard lisi(integer) 1得到排名在某个范围的元素列表
得到排名在某个范围的元素列表
按照元素分数从小到大的顺序返回索引从start到stop之间的所有元素(包含两端的元素) 语法:zrange key start stop [withscores]127.0.0.1:6379> zrange scoreboard 0 2 1) "zhangsan" 2) "wangwu" 复制代码按照元素分数从大到小的顺序返回索引从start到stop之间的所有元素(包含两端的元素) 语法:zrevrange key start stop [withscores]127.0.0.1:6379> zrevrange scoreboard 0 2 1) "wangwu" 2) "zhangsan" 复制代码如果须要得到元素的分数可以在命令末端加上 withscores 参数 ··· 127.0.0.1:6379> zrevrange scoreboard 0 2 withscores"wangwu""94""zhangsan""80" ···获取元素的排名从小到大 语法:zrank key member127.0.0.1:6379> zrank scoreboard zhangsan(integer) 0从大到小 语法:zrevrank key member
127.0.0.1:6379> zrevrank scoreboard zhangsan(integer) 1得到指定分数范围的元素
语法:zrangebyscore key min max [withscores] [limit offset count]
127.0.0.1:6379> ZRANGEBYSCORE scoreboard 90 97 WITHSCORES1) "wangwu"2) "94"3) "lisi"4) "97"127.0.0.1:6379> ZRANGEBYSCORE scoreboard 70 100 limit 1 21) "wangwu"2) "lisi"增加某个元素的分数
返回值是变动后的分数 语法:zincrby key increment member
127.0.0.1:6379> ZINCRBY scoreboard 4 lisi "101“得到凑集中元素的数量
语法:zcard key
127.0.0.1:6379> zcard scoreboard(integer) 3得到指定分数范围内的元素个数
语法:zcount key min max
127.0.0.1:6379> zcount scoreboard 80 90(integer) 1按照排名范围删除元素
语法:zremrangebyrank key start stop
127.0.0.1:6379> zremrangebyrank scoreboard 0 1(integer) 2127.0.0.1:6379> zrange scoreboard 0 -11) "wangwu"按照分数范围删除元素
语法:zremrangebyscore key min max
127.0.0.1:6379> zadd scoreboard 84 zhangsan (integer) 1127.0.0.1:6379> ZREMRANGEBYSCORE scoreboard 80 100(integer) 1运用商品发卖排行榜
需求:根据商品发卖量对商品进行排行显示 思路:定义商品发卖排行榜(sorted set凑集),Key为items:sellsort,分数为商品发卖量。
写入商品发卖量:
商品编号1001的销量是9,商品编号1002的销量是10 192.168.101.3:7007> ZADD items:sellsort 9 1001 10 1002商品编号1001的销量加1 192.168.101.3:7001> ZINCRBY items:sellsort 1 1001商品销量前10名: 192.168.101.3:7001> ZRANGE items:sellsort 0 9 withscoreskeys 命令常用命令keys 返回知足给定pattern 的所有key redis 127.0.0.1:6379> keys mylist"mylist""mylist5""mylist6""mylist7""mylist8"exists 确认一个key 是否存在 示例:从结果来看,数据库中不存在HongWan 这个key,但是age 这个key 是存在的 redis 127.0.0.1:6379> exists HongWan (integer) 0 redis 127.0.0.1:6379> exists age (integer) 1 redis 127.0.0.1:6379>del 删除一个key redis 127.0.0.1:6379> del age (integer) 1 redis 127.0.0.1:6379> exists age (integer) 0rename 重命名key 示例:age 成功的被我们改名为age_new 了 redis 127.0.0.1:6379[1]> keys "age" redis 127.0.0.1:6379[1]> rename age age_new OK redis 127.0.0.1:6379[1]> keys "age_new" redis 127.0.0.1:6379[1]>type 返回值的类型 示例:这个方法可以非常大略的判断出值的类型 redis 127.0.0.1:6379> type addr string redis 127.0.0.1:6379> type myzset2 zset redis 127.0.0.1:6379> type mylist list redis 127.0.0.1:6379>设置 key 的生存韶光Redis在实际利用过程中更多的用作缓存,然而缓存的数据一样平常都是须要设置生存韶光的,即:到期后数据销毁。
EXPIRE key seconds设置key的生存韶光(单位:秒)key在多少秒后会自动删除TTL key查看key剩余的生存韶光PERSIST key打消生存韶光PEXPIRE key milliseconds生存韶光设置单位为:毫秒
例子:
192.168.101.3:7002> set test 1 设置test的值为1OK192.168.101.3:7002> get test 获取test的值"1"192.168.101.3:7002> EXPIRE test 5 设置test的生存韶光为5秒(integer) 1192.168.101.3:7002> TTL test 查看test的生于天生韶光还有1秒删除(integer) 1192.168.101.3:7002> TTL test(integer) -2192.168.101.3:7002> get test 获取test的值,已经删除(nil)Redis 持久化方案Rdb 办法
Redis 默认的办法,redis 通过快照办法将数据持久化到磁盘中。
设置持久化快照的条件在 redis.conf 中修正持久化快照的条件:
持久化文件的存储目录
在 redis.conf 中可以指定持久化文件的存储目录
Rdb 的问题
一旦redis造孽关闭,那么会丢失末了一次持久化之后的数据。
如果数据不主要,则不必要关心。 如果数据不能许可丢失,那么要利用 aof 办法。
Aof 办法Redis 默认是不该用该办法持久化的。Aof 办法的持久化,是操作一次 redis 数据库,则将操作的记录存储到 aof 持久化文件中。
第一步:开启 aof 办法持久化方案。 将redis.conf中的appendonly改为yes,即开启aof办法的持久化方案。Aof文件存储的目录和rdb办法的一样。 Aof文件存储的名称在利用aof和rdb办法时,如果redis重启,则数据从aof文件加载。
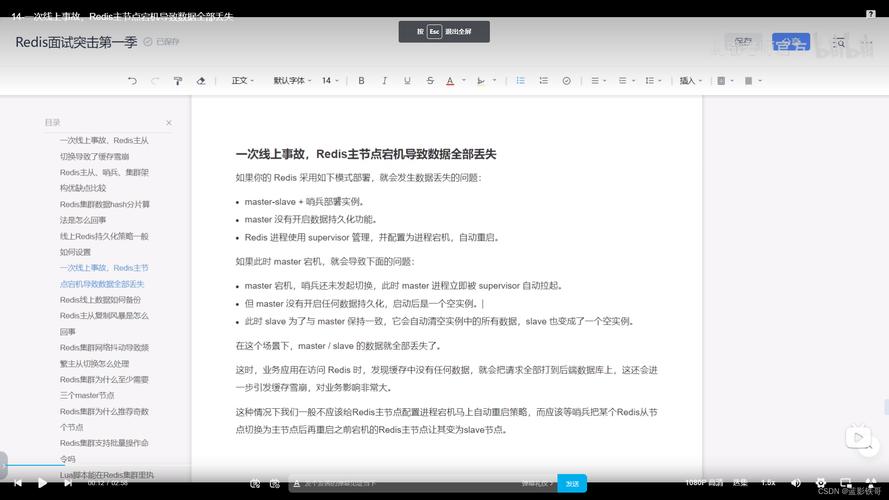
Redis 的主从复制什么是主从复制持久化担保了纵然redis做事重启也不会丢失数据,由于redis做事重启后会将硬盘上持久化的数据规复到内存中,但是当redis做事器的硬盘破坏了可能会导致数据丢失,如果通过redis的主从复制机制就可以避免这种单点故障,如下图:
解释:
主redis中的数据有两个副本(replication)即从redis1和从redis2,纵然一台redis做事器宕机其它两台redis做事也可以连续供应做事。主redis中的数据和从redis上的数据保持实时同步,当主redis写入数据时通过主从复制机制会复制到两个从redis做事上。只有一个主redis,可以有多个从redis。主从复制不会壅塞master,在同步数据时,master 可以连续处理client 要求一个redis可以即是主又是从,如下图:
主从复制设置主机配置无需配置
从机配置第一步:复制出一个从机 cp bin/ bin2 -r第二步:修正从机的 redis.conf 语法:slaveof masterip masterport slaveof 192.168.242.137 6379第三步:修正从机的 port 地址为 6380第四步:打消从机的持久化文件 rm -rf appendonly.aof dump.rdb第五步:启动从机 ./redis-server redis.conf第六步:启动6380的客户端 ./redis-cli -p 6380把稳: 主机一旦发生增编削操作,那么从机会将数据同步到从机中 从机不能实行写操作
Redis 集群redis-cluster 架构图架构细节: (1)所有的redis节点彼此互联(PING-PONG机制),内部利用二进制协议优化传输速率和带宽. (2)节点的fail是通过集群中超过半数的节点检测失落效时才生效. (3)客户端与redis节点直连,不须要中间proxy层.客户端不须要连接集群所有节点,连接集群中任何一个可用节点即可 (4)redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 卖力掩护node<->slot<->value Redis 集群中内置了 16384 个哈希槽,当须要在 Redis 集群中放置一个 key-value 时,redis 先对 key 利用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点.
redis-cluster 投票 容错(1)集群中所有master参与投票,如果半数以上master节点与个中一个master节点通信超过(cluster-node-timeout),认为该master节点挂掉. (2):什么时候全体集群不可用(cluster_state:fail)?
如果集群任意master挂掉,且当前master没有slave,则集群进入fail状态。也可以理解成集群的[0-16383]slot映射不完备时进入fail状态。如果集群超过半数以上master挂掉,无论是否有slave,集群进入fail状态。安装 Ruby集群管理工具(redis-trib.rb)是利用 ruby 脚本措辞编写的。
安装 rubysudo apt-get install ruby上传 redis-3.0.0.gem 到 linux安装 ruby 和 redis 接口 gem install redis-3.0.0.gem将 redis-3.0.0 包下 src 目录中的以下文件拷贝到 redis/redis-cluster/
cd /usr/local/redis/mkdir redis-clustercd /root/redis-3.0.0/src/cp redis-trib.rb /usr/local/redis/redis-cluster搭建集群
搭建集群最少须要 3 台主机,如果每台主机再配置一台从机的话,则最少须要6台机器。 端口设计:7001-7006
复制出一个7001机器 cp bin ./redis-cluster/7001 -r如果存在持久化文件,则删除 rm -rf appendonly.aof dump.rdb设置集群参数,修正redis.conf修正端口复制出7002-7006机器cp 7001/ 7002-rcp 7001/ 7003-rcp 7001/ 7004-rcp 7001/ 7005-rcp 7001/ 7006-r修正7002-7006机器端口创建文件 start-all.sh
cd 7001./redis-server redis.confcd ..cd 7002./redis-server redis.confcd ..cd 7003./redis-server redis.confcd ..cd 7004./redis-server redis.confcd ..cd 7005./redis-server redis.confcd ..cd 7006./redis-server redis.confcd ..修正文件权限
chmod u+x start-all.sh实行文件,启动六台机器
./start-all.sh创建集群 ./redis-trib.rb create --replicas 1 192.168.126.128:7001 192.168.126.128:7002 192.168.126.128:7003 192.168.126.128:7004 192.168.126.128:7005 192.168.126.128:7006连接集群
root@ubuntu:/usr/local/redis/redis-cluster/7001# ./redis-cli -p 7001 -c
-c 指定集群连接
查看集群信息查看集群信息192.168.126.128:7002> cluster infocluster_state:okcluster_slots_assigned:16384cluster_slots_ok:16384cluster_slots_pfail:0cluster_slots_fail:0cluster_known_nodes:6cluster_size:3cluster_current_epoch:6cluster_my_epoch:2cluster_stats_messages_sent:260cluster_stats_messages_received:260
192.168.126.128:7002> cluster nodes3a15e73dacb512745156535ae7f959acf65ae12e 192.168.126.128:7005 slave 23e173cdc0b7673dc28cae70efaabbc41308bfdc 0 1531452321139 5 connected2a58a53a5b10f7bd91af04128a6ed439d534c0ee 192.168.126.128:7001 master - 0 1531452322145 1 connected 0-5460d0808388485dd08f1a2ecdfe3d2b213742d0050d 192.168.126.128:7004 slave 2a58a53a5b10f7bd91af04128a6ed439d534c0ee 0 1531452318117 4 connected23e173cdc0b7673dc28cae70efaabbc41308bfdc 192.168.126.128:7002 myself,master - 0 0 2 connected 5461-109222af2312acc56552f9f73470f90d9a51973fc74d3 192.168.126.128:7006 slave 78faf92cfdbd12e1b27b270fb0798e67017f4d0b 0 1531452320132 6 connected78faf92cfdbd12e1b27b270fb0798e67017f4d0b 192.168.126.128:7007 master - 0 1531452319123 3 connected 10923-16383jedis连接集群
@Test public void jedisCluster() { // 创建jedisCluster Set<HostAndPort> nodes = new HashSet<>(); nodes.add(new HostAndPort("192.168.242.137", 7001)); nodes.add(new HostAndPort("192.168.242.137", 7002)); nodes.add(new HostAndPort("192.168.242.137", 7003)); nodes.add(new HostAndPort("192.168.242.137", 7004)); nodes.add(new HostAndPort("192.168.242.137", 7005)); nodes.add(new HostAndPort("192.168.242.137", 7006)); nodes.add(new HostAndPort("192.168.242.137", 7007)); JedisCluster cluster = new JedisCluster(nodes); cluster.set("s4", "444"); String result = cluster.get("s4"); System.out.println(result); cluster.close(); }利用 spring
配置 applicationContext.xml
<!-- 连接池配置 --><bean id="jedisPoolConfig" class="redis.clients.jedis.JedisPoolConfig"> <!-- 最大连接数 --> <property name="maxTotal" value="30" /> <!-- 最大空闲连接数 --> <property name="maxIdle" value="10" /> <!-- 每次开释连接的最大数目 --> <property name="numTestsPerEvictionRun" value="1024" /> <!-- 开释连接的扫描间隔(毫秒) --> <property name="timeBetweenEvictionRunsMillis" value="30000" /> <!-- 连接最小空闲韶光 --> <property name="minEvictableIdleTimeMillis" value="1800000" /> <!-- 连接空闲多久后开释, 当空闲韶光>该值 且 空闲连接>最大空闲连接数 时直接开释 --> <property name="softMinEvictableIdleTimeMillis" value="10000" /> <!-- 获取连接时的最大等待毫秒数,小于零:壅塞不愿定的韶光,默认-1 --> <property name="maxWaitMillis" value="1500" /> <!-- 在获取连接的时候检讨有效性, 默认false --> <property name="testOnBorrow" value="true" /> <!-- 在空闲时检讨有效性, 默认false --> <property name="testWhileIdle" value="true" /> <!-- 连接耗尽时是否壅塞, false报非常,ture壅塞直到超时, 默认true --> <property name="blockWhenExhausted" value="false" /></bean><!-- redis集群 --><bean id="jedisCluster" class="redis.clients.jedis.JedisCluster"> <constructor-arg index="0"> <set> <bean class="redis.clients.jedis.HostAndPort"> <constructor-arg index="0" value="192.168.101.3"></constructor-arg> <constructor-arg index="1" value="7001"></constructor-arg> </bean> <bean class="redis.clients.jedis.HostAndPort"> <constructor-arg index="0" value="192.168.101.3"></constructor-arg> <constructor-arg index="1" value="7002"></constructor-arg> </bean> <bean class="redis.clients.jedis.HostAndPort"> <constructor-arg index="0" value="192.168.101.3"></constructor-arg> <constructor-arg index="1" value="7003"></constructor-arg> </bean> <bean class="redis.clients.jedis.HostAndPort"> <constructor-arg index="0" value="192.168.101.3"></constructor-arg> <constructor-arg index="1" value="7004"></constructor-arg> </bean> <bean class="redis.clients.jedis.HostAndPort"> <constructor-arg index="0" value="192.168.101.3"></constructor-arg> <constructor-arg index="1" value="7005"></constructor-arg> </bean> <bean class="redis.clients.jedis.HostAndPort"> <constructor-arg index="0" value="192.168.101.3"></constructor-arg> <constructor-arg index="1" value="7006"></constructor-arg> </bean> </set> </constructor-arg> <constructor-arg index="1" ref="jedisPoolConfig"></constructor-arg></bean>
测试代码
private ApplicationContext applicationContext; @Before public void init() { applicationContext = new ClassPathXmlApplicationContext( "classpath:applicationContext.xml"); } // redis集群 @Test public void testJedisCluster() { JedisCluster jedisCluster = (JedisCluster) applicationContext .getBean("jedisCluster"); jedisCluster.set("name", "zhangsan"); String value = jedisCluster.get("name"); System.out.println(value); }















