
过程
比如博客的首页调用最新的20篇文章,相信不少同学在刚开始利用缓存的时候,会写下如下代码:

当然,模型中还能预加载每篇文章的分类,作者和tag信息,看起来没有任何问题,而且非常符合人类直觉。但是,放大到全站缓存来看,还是有很大的改进空间。
首先,首页缓存的是一个包含20个article工具的凑集,凑集的每一个单独的article工具除了在首页涌现,还会在分类、作者和tag等列表页涌现,还有文章详情页,而缓存的凑集数据没办法在这些页面间共用,重复缓存大量相同的article工具是对内存资源的很大摧残浪费蹂躏,假如article中的text字段content没有单独拆分出去,内存摧残浪费蹂躏得就更严重了。
其次,不像详情页数据改动很少,首页作为列表页来说,更新频率很高,设置的缓存韶光比较短,一样平常是分钟级别,缓存命中率并不高。
为了有效办理这两个问题,二级缓存就派上用场了,先说下自己对二级缓存的理解。
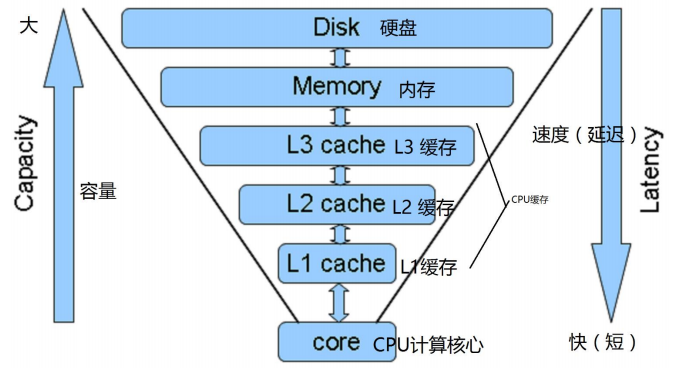
一级缓存可以算作是数据库里存的数据的一个镜像,只不过把数据从数据库搬到内存,一个key对应一条记录。key一样平常为表的标识符,比如key为articles:1存的value便是id=1的article工具。一级缓存韶光可以设得比较长,乃至forever也行,工具修正删除时,只要删除对应的key就行。
二级缓存可以算作业务逻辑的缓存,首页最新20条文章 就属于业务逻辑,只缓存这20条文章的id,极大地节省了内存占用。等须要用到详细的数据再去一级缓存取,一级缓存没有才去查询数据库,由于都是主键查询,不会造成表的描述,查询效率非常高。纵然二级缓存很快过期,一级缓存也不会失落效。
个人以为理解二级缓存最难的是要接管n+1查询这点,这个问题争议很大,明明各种ORM为了避免n+1利用了预加载,我们反而要抛弃它。包括我当初阅读范凯的《Web 运用的缓存设计模式》也心存迷惑,直到去理解了Hibernate二级缓存机制和自己在项目中的实践创造,还真是他说的那样。
拆分n+1条查询的办法,看起来彷佛非常违反大家的直觉,但实际上这是真理,我实践履历证明:数据库做事器的瓶颈每每是磁盘IO,而不是SQL并发数量。因此
拆分n+1条查询实质上因此增加n条SQL语句为代价,简化繁芜SQL,换取数据库做事器磁盘IO的降落
当然这样做往后,对付ORM来说,有额外的好处,便是可以高效的利用缓存了。
利用二级缓存来重构latestArticles方法
除了返回Collection,还可以返回Generator。
吐槽
在专栏发布界面,好不容易写到这里,结果手贱划了下浏览器刷新的鼠标手势,内心瞬间奔崩,砸电脑的心都有了 。虽然看提示有自动保存,可只有标题被保存了,内容还是空空如也。转眼想想历史上那些欠妥心毁了书稿写出世界名著的作家,自己也只有硬着头皮把内容回顾出来,所往后面的内容就一笔带过了。
更新与删除一级缓存的更新和删除可能通过模型的updated和deleted事宜来打消对应的缓存。二级缓存由于缓存韶光比较短,影响不大。
关联关系关联模型的缓存可能通过accessor来设置一个虚拟的属性来设置,比如在Article模型与Content模型是一对一的关系。
在Article中:















