
Solr是一个独立的企业级搜索运用做事器,它对外供应类似于Web-service的API接口。用户可以通过http要求,向搜索引擎做事器提交一定格式的XML文件,天生索引;也可以通过Http Get操作提出查找要求,并得到XML格式的返回结果。
Solr是Apache软件基金会下的子项目之一。

2. 事情事理
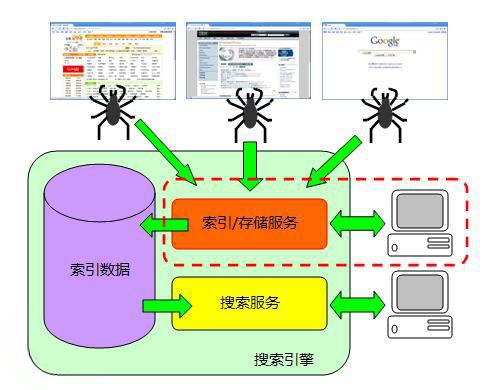
solr是基于Lucence开拓的企业级搜索引擎技能,而lucence的事理是倒排索引。那么什么是倒排索引呢?接下来我们就先容一下lucence倒排索引事理。
假设有两篇文章1和2:
文章1的内容为:老超在卡子门事情,我也是。
文章2的内容为:小超在鼓楼事情。
由于lucence是基于关键词索引查询的,那我们首先要取得这两篇文章的关键词。如果我们把文章算作一个字符串,我们须要取得字符串中的所有单词,即分词。分词时,忽略”在“、”的“之类的没故意义的介词,以及标点符号可以过滤。
我们利用Ik Analyzer实现中文分词,分词之后结果为:
文章1:
文章2:
接下来,有了关键词后,我们就可以建立倒排索引了。上面的对应关系是:“文章号”对“文章中所有关键词”。倒排索引把这个关系倒过来,变成: “关键词”对“拥有该关键词的所有文章号”。
文章1、文章2经由倒排后变成:
常日仅知道关键词在哪些文章中涌现还不足,我们还须要知道关键词在文章中涌现次数和涌现的位置,常日有两种位置:
a.字符位置,即记录该词是文章中第几个字符(优点是关键词亮显时定位快);
b.关键词位置,即记录该词是文章中第几个关键词(优点是节约索引空间、词组(phase)查询快),lucene中记录的便是这种位置。
加上涌现频率和涌现位置信息后,我们的索引构造变为:
实现时,lucene将上面三列分别作为词典文件(Term Dictionary)、频率文件(frequencies)、位置文件 (positions)保存。个中词典文件不仅保存有每个关键词,还保留了指向频率文件和位置文件的指针,通过指针可以找到该关键字的频率信息和位置信息。
3. 利用SolrJ管理索引库
利用SolrJ可以实现索引库的增编削查操作。
3.1 添加文档
第一步:把solrJ的jar包添加到工程中。
第二步:创建一个SolrServer,利用HttpSolrServer创建工具。
第三步:创建一个文档工具SolrInputDocument工具。
第四步:向文档中添加域。必须有id域,域的名称必须在schema.xml中定义。
第五步:把文档添加到索引库中。
第六步:提交。
@Testpublic void testSolrJAdd() throws SolrServerException, IOException { // 创建一个SolrServer工具。创建一个HttpSolrServer工具 // 须要指定solr做事的url SolrServer solrServer = new HttpSolrServer(\公众http://101.132.69.111:8080/solr/collection1\公众); // 创建一个文档工具SolrInputDocument SolrInputDocument document = new SolrInputDocument(); // 向文档中添加域,必须有id域,域的名称必须在schema.xml中定义 document.addField(\"大众id\公众, \"大众123\"大众); document.addField(\公众item_title\"大众, \"大众红米手机\"大众); document.addField(\公众item_price\"大众, 1000); // 把文档工具写入索引库 solrServer.add(document); // 提交 solrServer.commit();}
3.2 删除文档
3.2.1 根据id删除
第一步:创建一个SolrServer工具。
第二步:调用SolrServer工具的根据id删除的方法。
第三步:提交。
@Testpublic void deleteDocumentById() throws Exception { SolrServer solrServer = new HttpSolrServer(\"大众http://101.132.69.111:8080/solr/collection1\公众); solrServer.deleteById(\"大众123\"大众); // 提交 solrServer.commit();}
3.2.2 根据查询删除
@Testpublic void deleteDocumentByQuery() throws Exception { SolrServer solrServer = new HttpSolrServer(\公众http://101.132.69.111:8080/solr/collection1\"大众); //这边会根据分词去删 solrServer.deleteByQuery(\"大众item_title:红米手机\"大众); solrServer.commit();}
3.3 查询索引库
第一步:创建一个SolrServer工具
第二步:创建一个SolrQuery工具。
3 向SolrQuery中添加查询条件、过滤条件。。。
第四步:实行查询。得到一个Response工具。
5 取查询结果。
第六步:遍历结果并打印。
3.3.1 大略查询
@Testpublic void queryDocument() throws Exception { // 第一步:创建一个SolrServer工具 SolrServer solrServer = new HttpSolrServer(\公众http://101.132.69.111:8080/solr/collection1\公众); // 第二步:创建一个SolrQuery工具。 SolrQuery query = new SolrQuery(); // 第三步:向SolrQuery中添加查询条件、过滤条件。。。 query.setQuery(\"大众:\公众); // 第四步:实行查询。得到一个Response工具。 QueryResponse response = solrServer.query(query); // 第五步:取查询结果。 SolrDocumentList solrDocumentList = response.getResults(); System.out.println(\公众查询结果的总记录数:\"大众 + solrDocumentList.getNumFound()); // 第六步:遍历结果并打印。 for (SolrDocument solrDocument : solrDocumentList) { System.out.println(solrDocument.get(\"大众id\公众)); System.out.println(solrDocument.get(\"大众item_title\"大众)); System.out.println(solrDocument.get(\"大众item_price\"大众)); }}
3.3.2 带高亮显示
@Testpublic void searchDocumet() throws Exception { // 创建一个SolrServer工具 SolrServer solrServer = new HttpSolrServer(\公众http://101.132.69.111:8080/solr/collection1\"大众); // 创建一个SolrQuery工具 SolrQuery query = new SolrQuery(); // 设置查询条件、过滤条件、分页条件、排序条件、高亮 // query.set(\"大众q\"大众, \公众:\"大众); query.setQuery(\公众手机\"大众); // 分页条件 query.setStart(0); query.setRows(30); // 设置默认搜索域 query.set(\"大众df\"大众, \公众item_keywords\"大众); // 设置高亮 query.setHighlight(true); // 高亮显示的域 query.addHighlightField(\公众item_title\公众); query.setHighlightSimplePre(\"大众<div>\"大众); query.setHighlightSimplePost(\公众</div>\公众); // 实行查询,得到一个Response工具 QueryResponse response = solrServer.query(query); // 取查询结果 SolrDocumentList solrDocumentList = response.getResults(); // 取查询结果总记录数 System.out.println(\"大众查询结果总记录数:\"大众 + solrDocumentList.getNumFound()); for (SolrDocument solrDocument : solrDocumentList) { System.out.println(solrDocument.get(\公众id\"大众)); // 取高亮显示 Map<String, Map<String, List<String>>> highlighting = response.getHighlighting(); List<String> list = highlighting.get(solrDocument.get(\公众id\公众)).get(\公众item_title\"大众); String itemTitle = \"大众\公众; if (list != null && list.size() > 0) { itemTitle = list.get(0); } else { itemTitle = (String) solrDocument.get(\"大众item_title\"大众); } System.out.println(itemTitle); System.out.println(solrDocument.get(\"大众item_sell_point\"大众)); System.out.println(solrDocument.get(\"大众item_price\公众)); System.out.println(solrDocument.get(\"大众item_image\公众)); System.out.println(solrDocument.get(\"大众item_category_name\公众)); System.out.println(\公众=============================================\公众); }}
4. Solr做事器中的后台数据处理
这个实在是通过图形界面操作,只需手动填写查询条件,不须要进行代码处理。但是实际项目开拓中,还是须要进行代码编写的。
4.1 solr的根本语法
q 查询的关键字,此参数最为主要,例如,q=id:1,默认为q=:, fq (filter query)过虑查询,供应一个可选的筛选器查询。 返回在q查询符合结果中同时符合的fq条件的查询结果sort 排序办法,例如id desc 表示按照 “id” 降序 start 返回结果的第几条记录开始,一样平常分页用,默认0开始rows 指定返回结果最多有多少条记录,默认值为 10,合营start实现分页fl 指定返回哪些字段,用逗号或空格分隔,把稳:字段区分大小写,例如,fl= id,title,sortdf 默认的查询字段,一样平常默认指定 wt (writer type)指定输出格式,有 xml, json, php等 indent 返回的结果是否缩进,默认关闭hl 高亮 hl.fl 设定高亮显示的字段 hl.requireFieldMatch 如果置为true,除非用hl.fl指定了该字段,查询结果才会被高亮。它的默认值是false。 hl.usePhraseHighlighter 如果一个查询中含有短语(引号框起来的)那么会担保一定要完备匹配短语的才会被高亮。 hl.highlightMultiTerm如果利用通配符和模糊搜索,那么会确保与通配符匹配的term会高亮。默认为false,同时hl.usePhraseHighlighter要为true。 hl.fragsize 返回的最大字符数。默认是100.如果为0,那么该字段不会被fragmented且全体字段的值会被返回。
源码、更多资深讲师干系课程资料、学习条记请入群后向管理员免费获取,更有专业知识答疑解惑。入群即送代价499元在线课程一份。
QQ群号:560819979
拍门砖(验证信息):秋日密语















